| author: | zhaoyue-zephyrus |
| score: | 10 / 10 |
-
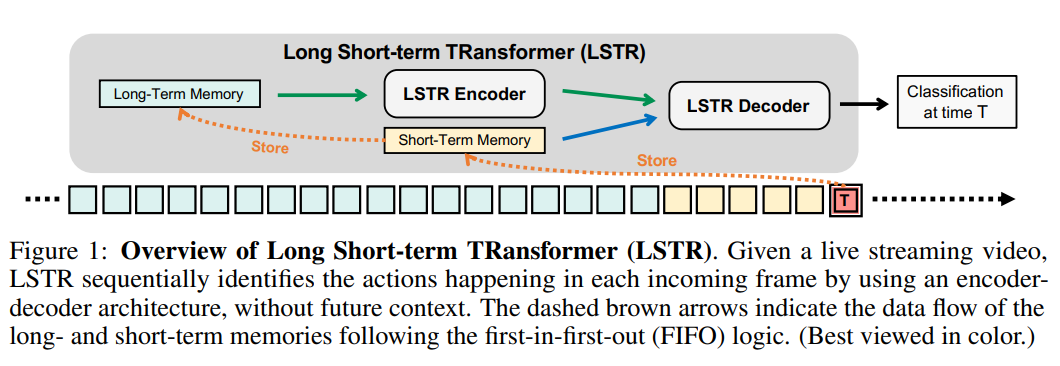
Long Short-Term Memories
-
short-term memory is a FIFO queue of \(m_S\) slots, \(f_{T}, \cdots, f_{T-m_S+1}\)
-
when a frame is older than \(m_S\) steps, it pops up and goes to the long-term memory;
-
long-term memory is a FIFO queue of \(m_L\) slots \(f_{T-m_S}, \cdots, f_{T-m_S-m_L+1}\)
-
\(m_S = 32, m_L = 2048\) at 4 FPS
-
-
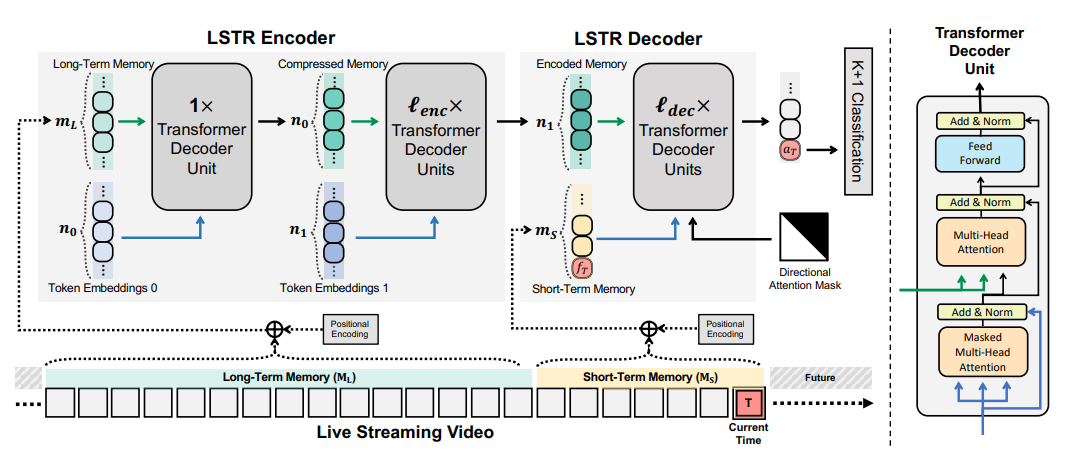
LSTR Encoder
-
Pure self-attention is computationally prohibitive for encoding long-term memory.
-
Transformer Decoder units:
-
Inputs: (1) learnable output tokens: \(\lambda\in\mathbb{R}^{n\times C}\) and (2) inputs tokens: \(\theta\in\mathbb{R}^{m\times C}\)
- \[\lambda' = \mathrm{SelfAttention}(\lambda) = \mathrm{Softmax}(\frac{\lambda\lambda^T}{\sqrt{C}})\lambda\]
- \[\mathrm{CrossAttention}(\sigma(\lambda'), \theta) = \mathrm{Softmax}(\frac{\sigma(\lambda')\theta^T}{\sqrt{C}})\theta\]
-
-
Two-Stage memory compression.
-
-
LSTR Decoder
- Use short-term memory as queries to retrieve useful information from the encoder.
-
Online inference with LSTR
-
The queries of the first Transformer decoder unit are fixed
-
In the cross-attention operation in the first stage, maintain the positional embedding matrix and update the feature matrix in a FIFO way
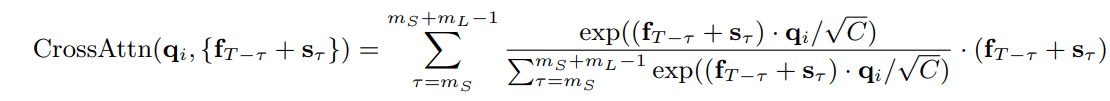
-
-
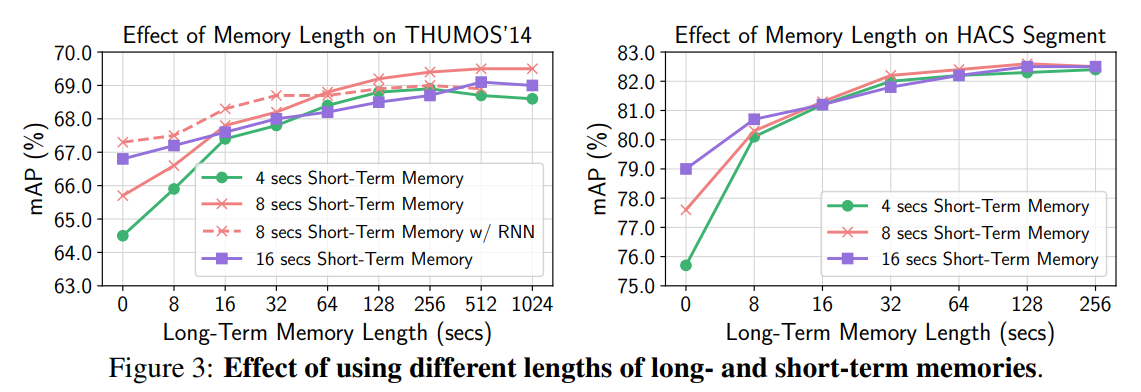
Experimental results
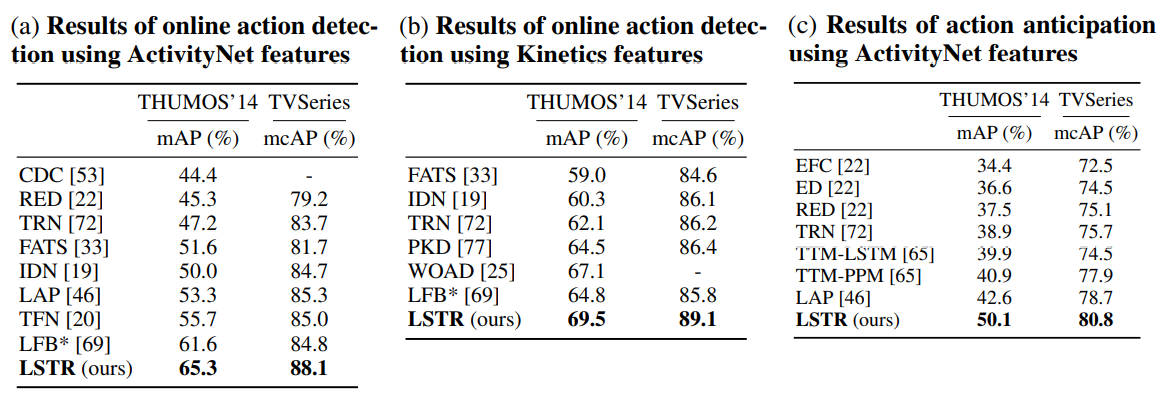
- Long-term memory is beneficial at up to 1024 seconds.
TL;DR
- Long short-term memory transformer based on cross attention.
- Enable trainable long-term memory and show improvement.
- Efficient implementation for online inference.