| author: | marcobueso |
| score: | 10 / 10 |
The core idea
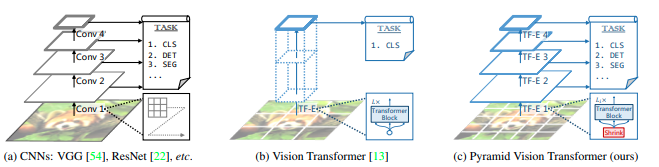
The authors present Pyramid Vision Transformer (PVT), a convolution-free backbone which has improved performance in comparison to a Visual Transformer (ViT). Unlike the ViT, which generally yields low-resolution outputs and has a high computational and memory cost, PVT can achieve high output resolution, while maintaining a low computational and memory cost.
It presents a progressive shrinking pyramid to reduce the computations of large feature maps.
ViT is good for image classification, but has two drawbacks:
(1) its output feature map is single-scale and low-resolution
(2) its computational and memory costs are relatively high even for common input image sizes
How is it realized (technically)?
(1) taking fine-grained image patches (i.e., 4×4 pixels per patch) as input to learn high-resolution representation, which is essential for dense prediction tasks;
(2) introducing a progressive shrinking pyramid to reduce the sequence length of Transformer as the network deepens, significantly reducing the computational cost;
(3) adopting a spatial-reduction attention (SRA) layer to further reduce the resource consumption when learning high-resolution features.
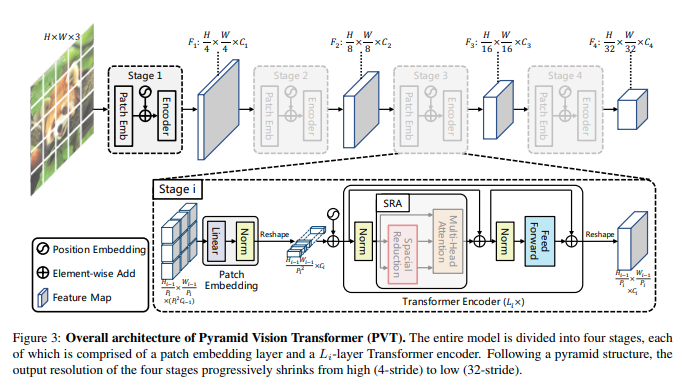
There’s four stages, all of which have similar architecture. On the first stage, assuming an input of size H x W x 3, it gets divided into HW/4x4 patches, each of size 4x4x3. The flattened patches get passed through a linear projection and embedded patches of size (HW/4x4) x C. These are then passed through a Transformer encoder with L1 layers, and the output is shaped into a feature map F1, of size (HW/4x4) x C. This process goes on for the remaining 3 feature maps (with strides of 8, 16, and 32 ouxels with respect to the input image).
With the feature pyramid: {F1, F2, F3, F4}, the method can be applied to many downstream tasks.
PVT’s closest model is the ViT. They’re both models without convolutions. The primary difference between them is the pyramid structure.
The PVT’s progressive shrinking pyramid generates multi-scale feature maps like a traditional CNN backbone.
The SRA layer is also a main feature of the PVT, which allows for high-resolution feature maps, and reduces computational and memory costs.
Performance
PVT was compared with ResNet and ResNeXt, on multiple downstream tasks. I will not go over all the results, but some of the most impactful ones are below:
- Image classification on ImageNet - Top-1 Error (%): PVT - 24.9 v. ResNet18 - 30.2
- Object Detection on COCO - Average Precision (AP): PVT-Tiny - 36.7 v. ResNet18 - 31.8
- Semantic Segmentation on ADE20K - mIoU (%): PVT-Small - 39.8 v. ResNet50 - 36.7 (w/ ~equal parameters and GFLOPs)
PVT-Large+Semantic FPN archives the best mIoU of 44.8, which is very close to the state-of-the-art performance of the ADE20K benchmark.
What interesting variants are explored?
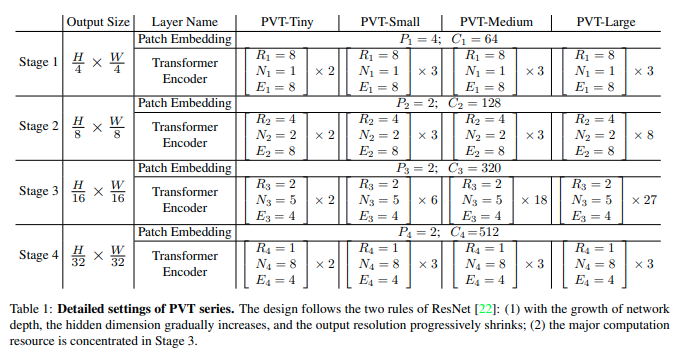
The authors compared deeper vs wider networks on PVT, and concluded that deeper models (PVT-Medium) work better than wide ones (PVT-Small-Wide).
They detail the specificaitons of the different PVTs in the following table:
TL;DR
- The Pyramid Vision Transformer (PVT) is the first pure Transformer backbone designed for various pixel-level dense prediction tasks. It allows for models without convolutions.
- PVT can achieve high output resolution, while maintaining a low computational and memory cost.
- PVT outperformed ResNet and ResNeXt in multiple tasks, and opens possibilities for further exploration on transformers.