| author: | zhaoyue-zephyrus |
| score: | 10 / 10 |
The main idea of the paper is to increase the network depth by two aspects. The first is a deeper compositional module called Inception which is composed of convolutional layers with multiple sizes; the second is to repeatedly stack Ineption modules, leading to a 22-layer deep GoogLeNet model, which is significantly deeper than a 5-layer LeNet/AlexNet.
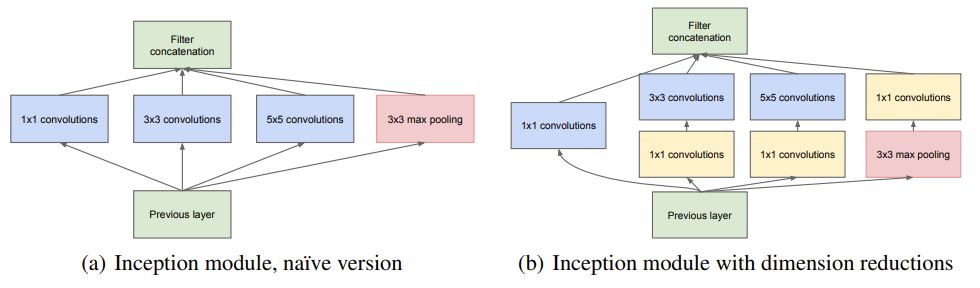
Uniformly increasing the network size will drastically increase both number of parameters and computational resources. Hence, the motivation behind the Inception module is to introduce sparsity into dense connected convolutional layers, so that as the required computation is still within budget when the network goes deeper. However, non-uniform sparse matrix calculation is inefficient to compute while dense connection is efficiently parralizable. So it is more feasible to attain the sparsity via a composition of multiple densely connected components, i.e. standard convolutional layers with varying kernel sizes. This is the naïve version of Inception module, which is essentially:
-
passing the incoming feature into four layers of 1x1 conv, 3x3 conv, 5x5 conv, and a 3x3 max pooling; and
-
concatenating the feature maps obtained from above.
The naïve realization is inefficient because a 5x5 convolution at higher level is still expensive because it is wider (larger channel) and takes larger proportion compared to 1x1 and 3x3.
So, the efficient version is to apply 1x1 conv for dimension reduction, as is done in NiN, before 3x3 and 5x5 conv.
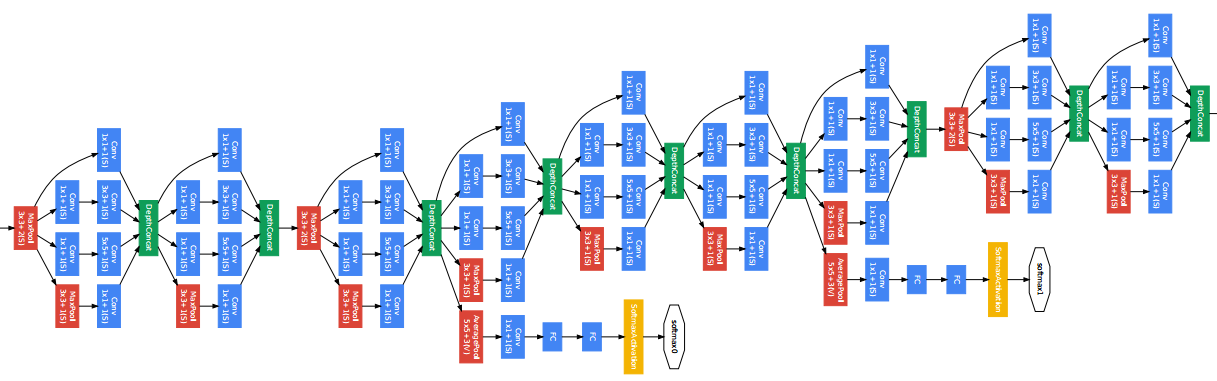
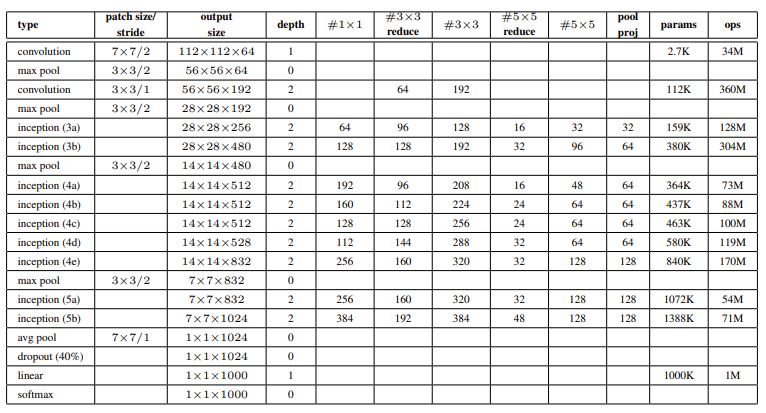
The final GoogLeNet is a 22-layer deep network which has two base convolution layers (7x7 with stride of 2 and 3x3 with stride of 1) plus max pooling at the bottom and 9 replica of Inception modules with increasing channels. (See specs at below table) The total number of individual convolution blocks is 100.
Due to the increased depth, the paper proposes to insert two auxiliary classifiers in the intermediate layers (see two octagons in the first figure) to encourage gradient propagation through all layers. The overall training loss is the classification loss at the last classification layer plus two auxiliary loss with a discounted weight of 0.3. The auxiliary classifiers are inserted after Inception-4a and -4d respectively, and are composed of (1) an average pooling with 5x5 filter size and stride 3, (2) a 1x1 conv with 128 channels + ReLU, (3) a 1024-d fc layer + ReLU, and (4) dropout. The auxiliary classifier is only used when training and is dropped during inference.
The Inception is winner of 2014 ImageNet Challenge and surpasses AlexNet by 56.5% relative reduction and ZF-Net (2013 challenge winner) by 40%, which has small deviations from AlexNet.
TL;DR
- Inception module which is a composition of multi-scale convolution layers with varying kernel sizes following 1x1 convolutions
- A 22-layer deeper network (GoogLeNet) which is a stack of multiple Inception modules.
- Auxiliary classifier inserted in the intermediate layers for better gradient propagation.