| author: | saikm200022 |
| score: | 8 / 10 |
Summary - Sequence to Sequence Learning with Neural Networks, Sutskever, Vinyals, Le; 2014
What is the core idea?
Deep Neural Networks are being used today for all kinds of difficult tasks such as image detection and speech recognition. However, DNNs are not suitable for sequence to sequence tasks because the dimensionality of input and output sequences can be arbitrary. This paper suggests a Deep Learning approach that is suitable for a sequence to sequence task by bypassing its limitation of requiring fixed dimensionality input and output.
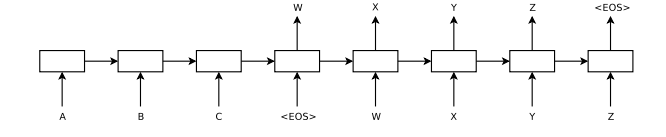
How is it realized (technically)?
The model in the paper uses two LSTMs: one for the input and output sequences respectively. These LSTMs were relatively deep with four stacked layers and a final softmax layer over the LSTMs output.
The paper’s training algorithm performed Maximum Likelihood Estimation (MLE) to maximize the below expression. At the end of each time step, the model computes a vector of vocabulary size that contains the distribution over the vocabulary given the input. Based on the output of LSTM, the most likely translation is one whose product of probabilities across time steps is the largest.
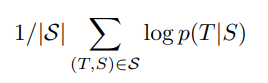
The most likely translations after training were found using a left-to-right beam search algorithm, which is independent of the MLE training goal. The beam size is relevant to determining the best number of translations that are kept at every time step. Smaller beam sizes indicate greedier translation selections.
The paper also took the 1000 most likely translations from the baseline Statistical Machine Translation Model (SMT) and rescored them using the log probabilities of each translation hypothesis with their model. The model was trained using Stochastic Gradient Descent without momentum with a batch size of 128 random sentences.
Another unique implementation detail was that they reversed the input LSTM. Instead of reading sentences into the model from left to right, they read the input sentences from right to left.
How well does the paper perform?
The model was used on the WMT’14 English to French Machine Translation task. The paper trained the model on a subset of 12 million sentences with vocabulary size of 348 million and 304 million words for French and English respectively.
Success was based on BLUE score - typically computed by comparing a translated sentence with some reference translation checking for some overlap. The higher the score, the closer the model’s output translations were to the reference translations.
5 LSTMs with different initialization and ordering of batches plus a beam size of 12 were able to achieve a BLEU score of 34.81, which was larger than what was achieved by the SMT baseline.
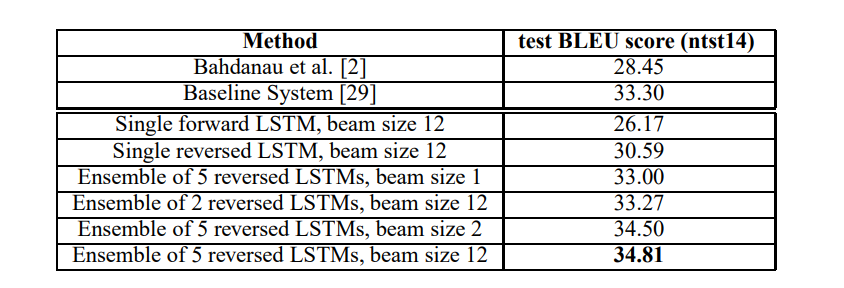
The paper also found that rescoring the baseline’s 1000 best lists with their own 5 reversed LSTMs lead to a BLEU score of 36.5 which is very close to the best WMT’14 result of 37.0. Overall, this paper states this was the first time a neural translation approach achieved significant results on a sequence to sequence task.

What interesting variants are explored?
I found it interesting that the paper implemented reversed LSTMs. Typical LSTMs read sentences from beginning to end, but this paper reverses the sentences and reads input backwards. Apparently, this significantly helped their model’s performance by increasing BLEU score by about 4 - 5. They theorize that because source words are closed to the target words in the decoder, there is fewer “minimal time lag”. Since the source and target words are initially closer to each other, it is easier for the model to draw connections between the input and output sentences early on during decoding.
TL;DR
- Sequence to sequence tasks with deep learning models was challenging because they require a fixed dimensionality of input and output sequences
- LSTMs can be used to represent an input sequence as a large fixed dimensionality vector that can be used to translate into an output sequence of arbitrary length
- First example of neural approach outperforming baseline statistical machine translation and performance relatively near best approach