| author: | zhaoyue-zephyrus |
| score: | 10 / 10 |
MobileNetV2 dives deeper into the depthwise separable convolution and proposes a better alternate: inverted residual with linear bottleneck.
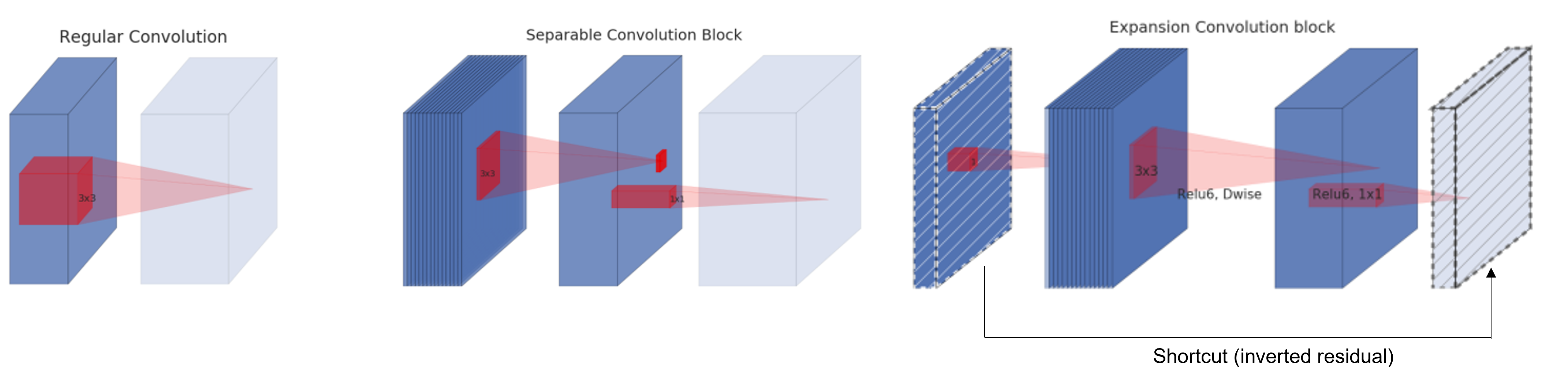
It has two significant modifications:
-
Simply decreasing width multiplier (\(\alpha\)) is suboptimal for performing dimensionality reduction on a “manifold of interest” due to the presence of nonlinear activation. A better solution is to remove nonlinearity when performing dimensionality reduction, leading to a linear bottleneck layer (bottleneck refers to projecting onto a lower dimension). Feature dimension can be expanded once again later and efficiently processed using depthwise convolution.
-
Similar to ResNet, MobileNetV2 add shortcuts between the linear bottleneck. The difference is that in ResNet the original residual connect the layers with larger number of channels (the reason of naming it inverted residuals).
- theoretical intuition: the bottleneck layer contains all necessary information compactly (the capacity of layer/network) while the expansion layer (depthwise conv) is an implementation to perform transformation (expressiveness).
- implementation perspective: this inverted residual is more memory efficient.
To see this, we decompose each inverted residual module into the following:
\[F(x) = [A \circ \mathcal{N} \circ B](x),\]where \(A\) and \(B\) are two linear transformation and \(\mathcal{N}\) is the depthwise convolution plus the rest of nonlinearities, i.e. \(\mathrm{ReLU6} \circ \mbox{dwise-conv} \circ \mathrm{ReLU6}\).
It can be rewritten as a sum of several chunks so that memory can be reused across chunkes (memory efficiency is important for many mobile applications):
\[F(x) = \sum_{i=1}^t [A_i \circ \mathcal{N} \circ B_i](x)\]The implementation trick is possible because \(\mathcal{N}\) is per-channel (both depthwise conv and ReLU).
On ImageNet, MobileNetV2 can beat MobileNetV1 by 1.4% with nearly half FLOPs. It can be adopted for Single-Shot Detector (SSD) and the resultant MobileNetV2+SSDLite outperforms YOLOv2 with 20x more efficient and 10x smaller.
TL;DR
- Improved version of depthwise convolution module equipped with linear bottleneck and inverted residual.
- Inverted residual module has a memory-efficient implementation (mobile-friendly).
- Significant improvement on accuracy, FLOPs, and CPU runtime on image classification, and objection detection.