| author: | trowk |
| score: | 9 / 10 |
What is the core idea?
As of 2016, generating region proposals to perform object detection was a ``computational bottleneck.’’ In order to speed up regional proposal networks, the authors propose a new convolutional neural network called a Regional Proposal Network (RPN). This RPN shares convolutional layers with object detection networks like Fast R-CNN to drastically increase performance.
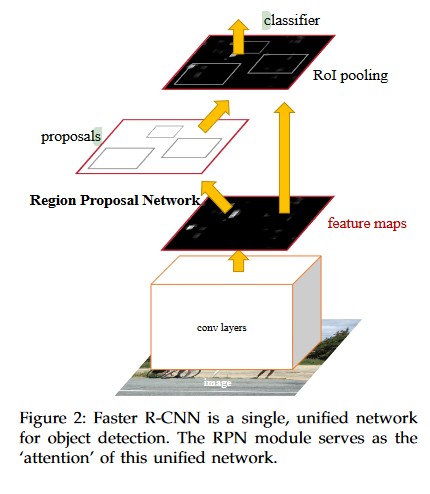
How is it realized (technically)?
The final model used to detect images is called Faster-CNN. It is composed of two main parts: the RPN for region proposal and a Fast R-CNN detector that detects objects on the proposed regions.
The RPN part of the network first sends an image through a shared convolutional network to generate a feature map. This feature map is fed in \(n \times n\) chunks using a sliding window to another convolutional network that generates a new, lower dimensional feature vector for each chunk of the image. These new features are then sent through two different fully-connected neural networks: a box-regression layer (reg) and a box-classification layer (cls). Let an anchor be defined as the center of the \(n \times n\) sliding window in conjunction with some scale and aspect ratio. The box-regression layer takes an anchor and outputs a bounding box. The box-classification outputs probabilities of the anchors containing objects.
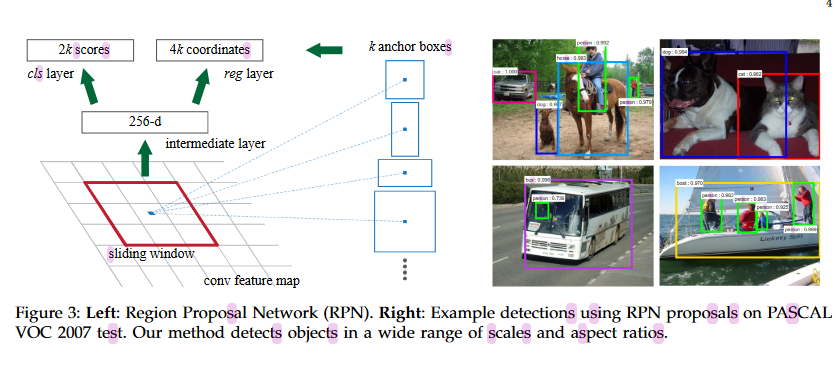
When training the RPN, the authors used binary labels to denote if an anchor contained an object or not. If an anchor either contained the highest Intersection-over-Union (IoU) overlap with a ground-truth region or if the IoU was over 0.7, it received a positive label. If the IoU value is below 0.3, the anchor is assigned a negative value. Otherwise, it is assigned 0 (anchors assigned 0 do not impact the loss). The loss function for a single image is then
\[L(\{p_i\}, \{t_i\}) = \frac{1}{N_{cls}}\sum_i L_{cls}(p_i, p_i^*) + \frac{1}{N_{reg}}\sum_i p_i^* L_{reg}(t_i, t_i^*)\]Essentially, only anchors with positive and negative values are considered to prevent biases to negative samples. The binary loss for all the anchors from the cls network are summed, and a different regression loss is used for reg and are added only if the ground-truth of the anchor is 1. The terms are weighted by the $N$ values.
Now, to train the Fast R-CNN in addition to the RPN, the authors used a four-step method. First, the RPN is initialized and trained to propose regions. Then, a separate convolutional network is used by Fast R-CNN to detect object from the proposals generated by RPN in the first step. Then, in the third step, the convolutional neural network from the Fast R-CNN is used to initialize the first part of the RPN. The authors fix this network and fine tune the networks that are not shared with Fast R-CNN. Then, for the final step, Fast R-CNN is fine tuned with the shared layers fixed. This method is how Faster R-CNN is trained with a shared convolutional neural network between RPN and Fast R-CNN.
Notably, anchors with bounding boxes that passed the boundaries of their image were discarded. This drastically decreased the amount of anchors that needed to be considered by the Fast R-CNN and removed some difficult error-terms. Furthermore, non-maximum suppression (NMS) was used to remove anchors with IoU scores below 0.7. This also drastically reduced the number of proposals and increased the training speed.
How well does the paper perform?
An experiment was run on PASCAL VOC 2007 detection benchmark, a data set consisting of 5 thousand train and test images over 20 object categories. Several different object proposal methods were used in conjunction with Fast R-CNN and the resulting detection mean Average Precision scores (mAP) were compared. RPN was found to achieve competitive results even when generating fewer proposals. Several ablation experiments were also run on this dataset.
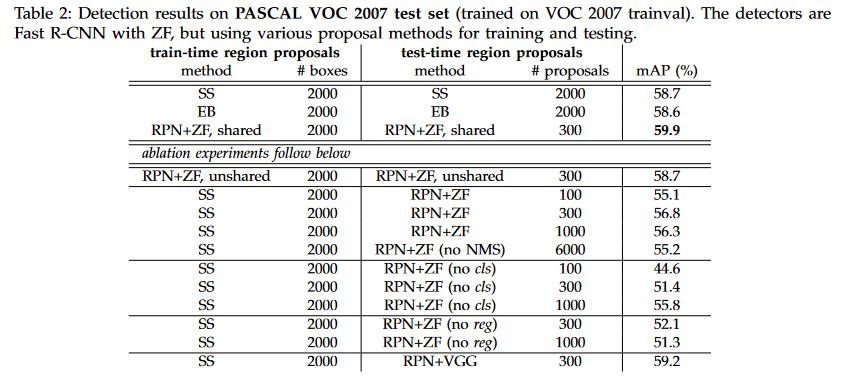
An experiment was also run where the shared convolutional layers used the VGG-16 network. When compared to the Selective Search (SS) object proposal method, RPN acheived competitive performance at a fraction of the time SS took.

Experiments were also run on the COCO dataset, a dataset with 80K training images and 40K validation images. The results were competitive when compared to SS.
TL;DR
- RPNs use shared convolutional layers with Fast R-CNN to speed up object region proposals
- Anchors, feature vectors with an assigned aspect ratio and scale, are used to generate several different bounding boxes quickly.
- RPN can perform competitively with fewer proposals to other region proposal methods.