| author: | joshpapermaster |
| score: | 7 / 10 |
This paper introduces scenarios where the ADAM optimizer fails to converge to the best solution. As a solution, the paper provides variants of the ADAM optimizer that not only succeed in fixing the specific issues pointed out by the paper, but also often improve training.
The main issue with ADAM and similar variants is that they use exponential moving averages, which puts a major focus on the past few gradients. As a result, large gradient values with important information are quickly multiplied by a decaying factor to have very little influence.
There are three theorems presented in this paper on the non-conergence of ADAM, with the third one being the most specific:
For any constant β1, β2 ∈ [0, 1) such that β1 < β2^(1/2), there is a stochastic convex optimization problem where ADAM does not converge to the optimal solution
- β1 and β2 here refer to the “forgetting factor” for the momentum (m) and the exponential moving average (v)
- There is the potential for non-zero average regret in this situation, which basically means the influence of the gradient can’t keep up with bad decisions, thus the the network is not converging or learning anything
- Stochastic gradient descent does not have this problem because the learning rate is non-increasing
- There is no constant that can be put into the denominator of the ADAM update step to counteract this issue happening to some constant β1, β2
- This theorem specifies that this is a real issue for practical problems, and the only real solution to cover all scenarios would be to have a different β1 and β2 for each dimension
- However, that creates additional hyperparameters
Solution: AMSGrad
- AMSGrad basically keeps track of the largest gradient to use as a dynamic way to normalize the gradients
- This ensures that the learning rate does not increase
- But avoids the downside of ADAGRAD, which is that the learning rate decreases too much
Here is the outline of the generic adaptive method. The m term refers to the momentum and the v term refers to the averaging function.

The key difference in AMSGrad from the generic adaptive method is seen when the maximum gradient is kept from the previous set. This recursively ensures the largest gradient is kept track of. By doing so, the learning step size is non-increasing.

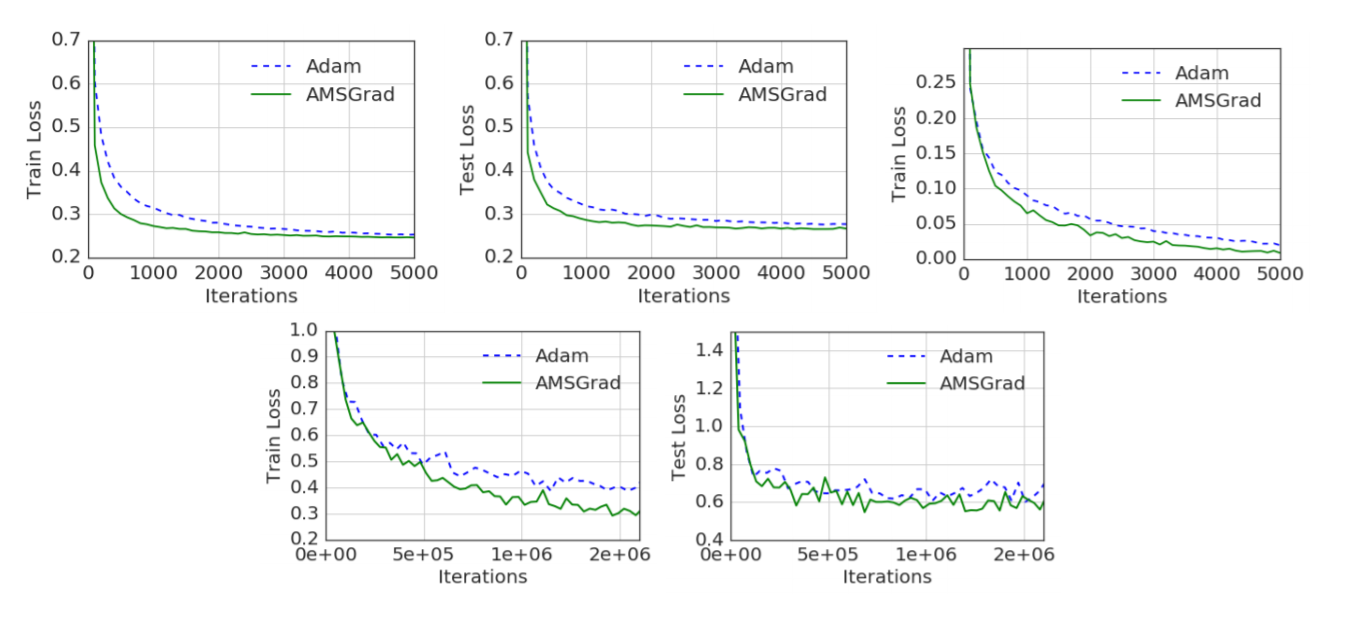
The training and test lost for AMSGrad clearly beats ADAM in all tests. Even if ADAM does manage to converge to the optimal solution, the issues brought to light in this paper still likely slow it down.
The paper also presents an alternative solution called ADAMNC
- The main idea is to dynamically change β1 and β2 so that the conditions for non-convergence are never met for long
TL;DR
- There are certain situations that come up practically where ADAM slows down or entirely fails to converge due to the exponential moving average increasing the learning rate over time
- This paper provides a solution called AMSGrad that normalizes the exponential moving average of the gradients using the largest seen gradient so that the learning rate does not increase
- AMSGrad avoids the issues present in ADAM, while also speeding up training in many situations