| author: | zhaoyue-zephyrus |
| score: | 8 / 10 |
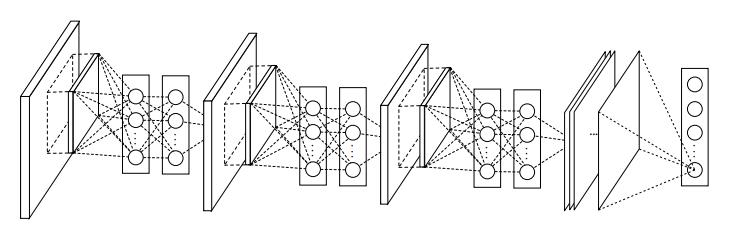
This paper has two main ideas:
-
Improve the abstraction ability of convolution layers by attaching an additional nonlinear function approximator, instantiated by a multi-layer perceptron.
-
Replace the last two fully-connected layers (LeNet-5, AlexNet) with a global average pooling layer.
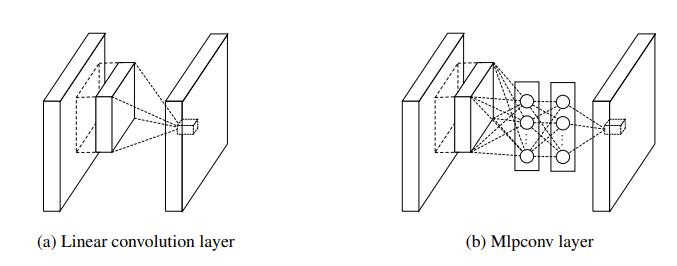
The paper argues that the convolution filter is a generalized linear model (GLM). Nonlinearity is realized by the following nonlinear activation function (tanh previously and ReLU nowadays). Hence, the abstraction ability is limited. Previous efforts were focused on an making convolution layers wider (a larger number of channels). This paper proposes to make each convolution layer deeper by appending a 2-layer MLP (fc + ReLU), so that each local patches will undergo two more layers of abstraction. The revised layer is called mlpconv layer because it is instantiated via a conv+ReLU and two fc+ReLU. The added fc layer can also be viewed as a special case of convolution whose kernel size is 1x1 (1x1 conv), which is more helpful to understand NiN. The 1x1 convolution will later be shown to be an effective way of dimensionality reduction (though often one layer instead).
The second improvement is replacing the last two fc layers with a Global Average Pooling (GAP) layer. The two fc layers are also a great burden for storage (16M parameters for a single 4096-in-4096-out fc layer) and training (prone to overfitting). The paper removes this by making the last mlpconv layer output a Cxhxw feature map where the number of channel is exactly the number of categories for final classification and h, w for a downsampled size. Therefore, each feature map (viewed per channel) corresponds to a heat map for a specific class, and can be interpreted as the category’s confidence map. To obtain the final class-level prediction, a global average pooling layer is applied to the feature map. It has the following advantages:
- This structural regularizer is effective for preventing overfitting as it introduces no additional parameters to the model.
- This design sweeps the floor for fully-convolutional design (FCN [1]) if GAP is removed.
- Also, GAP is later shown to be capable of discriminative localization [2] and therefore serves as a strong baseline for weakly-supervised object detection (localizing object with single class label, i.e. without exact object box)
[1] Long, Shelhamer, Darrell. Fully convolutional networks for semantic segmentation. CVPR 2015
[2] Zhou, Khosla, Lapedriza, Oliva, Torralba. Learning Deep Features for Discriminative Localization. CVPR 2016
The paper conducts experiments on CIFAR-10, CIFAR-100, SVHN, MNIST, which was satisafactory from the perspetive of that time but may be insufficient in today’s criterion. But the ideas presented are refreshing and repeatedly used by the following methods.
TL;DR
- NiN: ordinary kxk convolution (k>1) + 1x1 convolution;
- Generating one feature map per category at the last conv layer sweeps floor for fully-connected networks
- Global Average Pooling (GAP) serves as an effective structure regularizer and gets rid of the white elephant of last two FC layers in AlexNet.