| author: | slycane9 |
| score: | 8 / 10 |
- What is the core idea?
Object Detection models that were state-of-the-art at the time did not perform well on a long-tail large vocabulary (ie classes with low frequenices in training were often not detected). The authors show that the classifier weight norm for low frequency classes in skewed datasets falls to 0, making them almost impossible to detect.
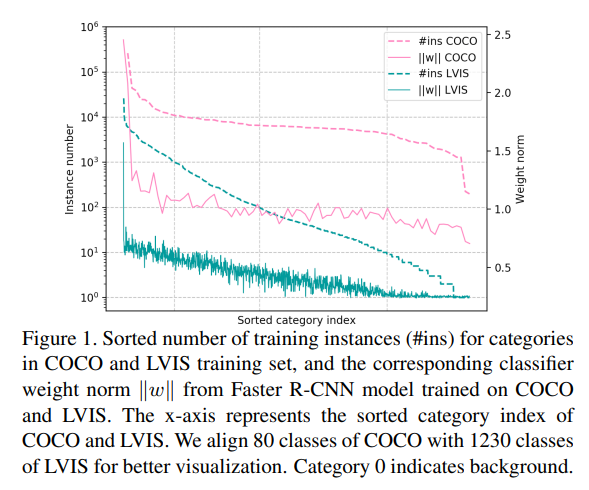
Other methods such as resampling data to have more tail-classes (which causes overfitting) and loss re-weighting (which requires complex changes in implementation based on the model backbone and framework) fall short in solving this issue.
Balanced Group Softmax (BAGS) fixes this issue by dividing all training classes into groups based on frequency and softmaxing them to determine the ouput class probability vector.
- How is it realized (technically)?
The main idea behind BAGS is simple. We only want classes with similar frequency counts to compete with each other. This avoids classes in the long-tail section being ignored due to the overwhelming presence of the high-frequency head classes. This paper decided after testing that 4 groups were best plus 1 group used for the background classification (since this class will be very common). The split of the 4 groups in frequency was 0-9,10-99,100-999,1000+.
Softmax is then applied to each group individually. It was chosen due to its ability to differentiate classes from each other (which we can safely do now that we have grouped them by frequency) and to avoid false positives.
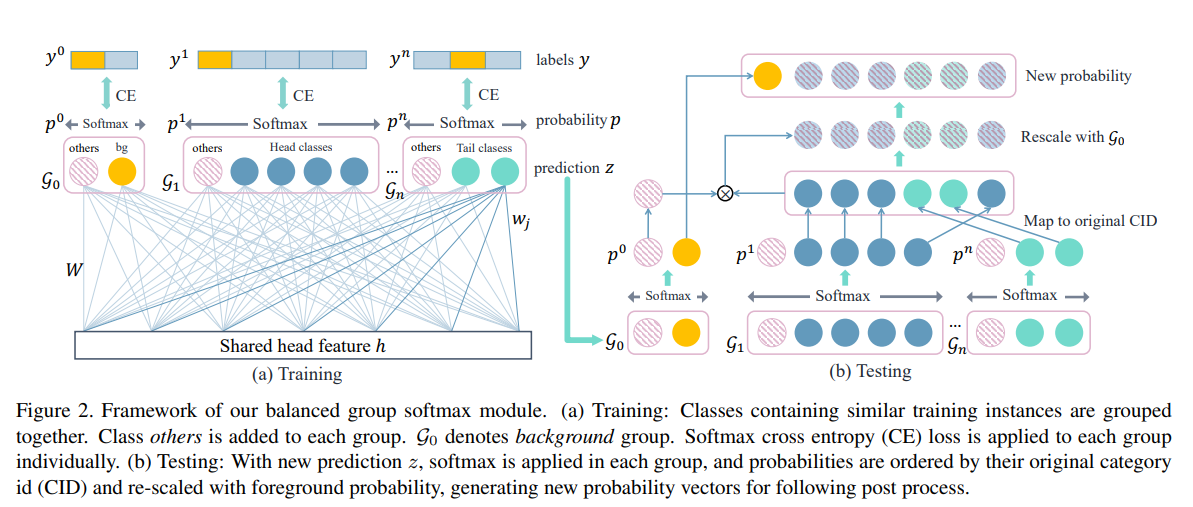
With the current BAGS setup, we have an issue of 1 class in each group having the highest probability score, which does not help us decide which of the 4 to choose. To fix this, the authors added a category called “other” in each group. This avoids false positives that may form in a group by giving the group the option to essentially select none of the classes in that group (by selecting “other”). The ratio of “others” would naturally be high, so a sample ratio \(\beta\) was used to control the amount of “other” proposals for training.
For inference, BAGS ignores the “other” category and outputs one probability matrix with all the category IDS. These probabilities are calculated using a softmax in each group and then scaling each probability by the probability of a foreground proposal (ie the chance of a detection class not being the ‘background’).
- How well does the paper perform?
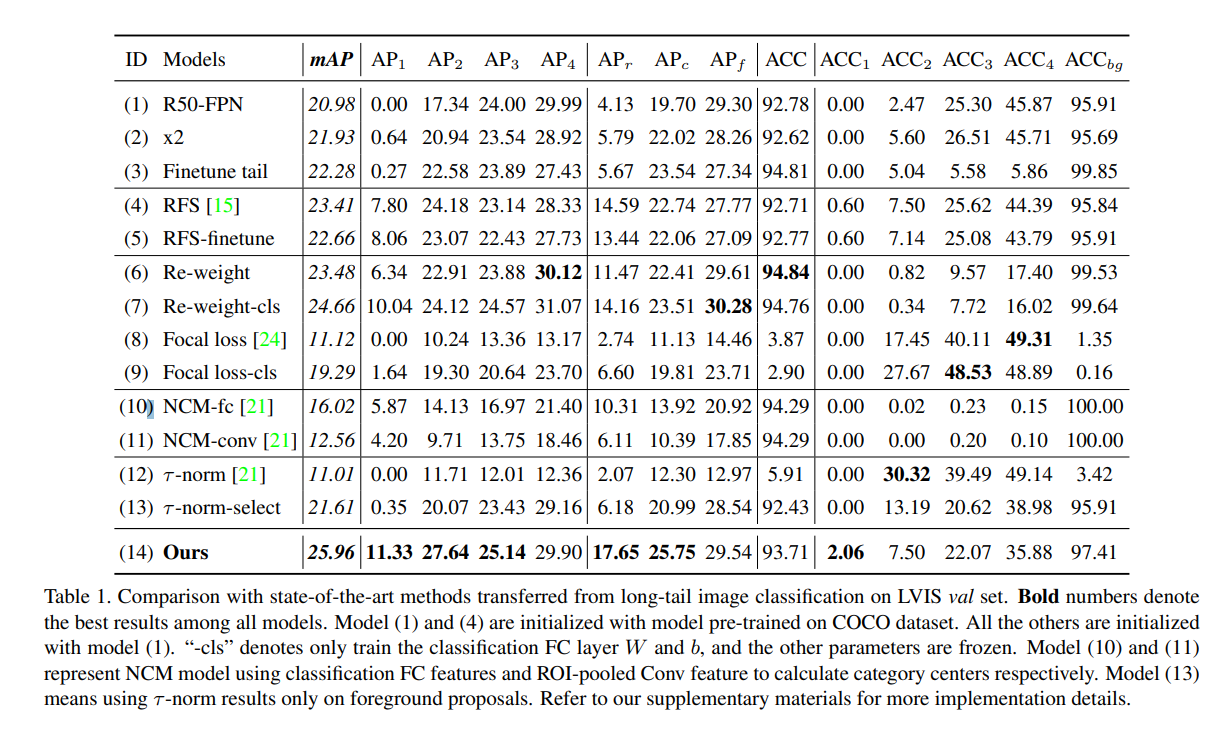
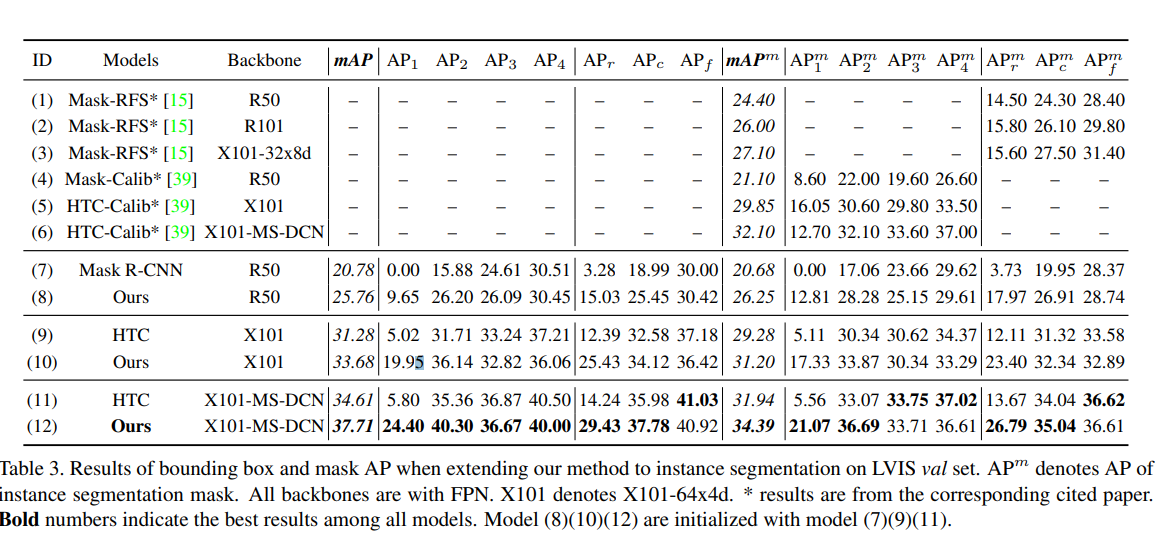
The paper performs very well. BAGS was implemented on a ResNet-50-FPN backbone, and outperformed all state-of-the-art-models’ mAP scores on the LVIS (a long-tail skewed dataset). The general trend for BAGS had the head group (AP4) with a slightly lower mAP but much higher mAP scores in the long-tail groups.
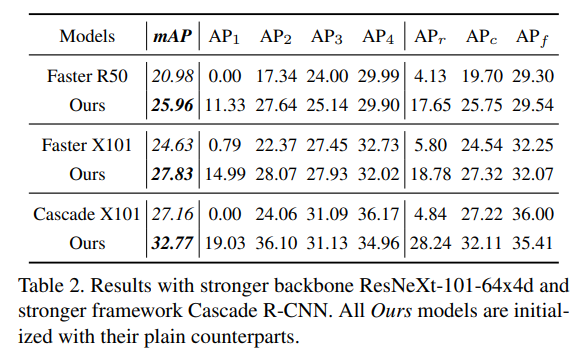
The improvements from BAGS applied to other model backbones as well.
Instance segmentation yielded similar results.
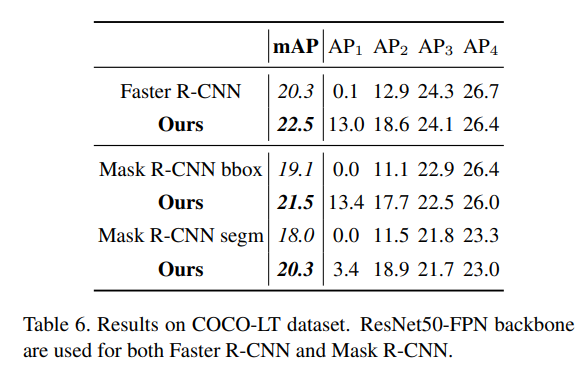
Finally, a more balanced COCO dataset was tested on, and BAGS yielded higher mAP scores there too.
TL;DR
- Object Detection Models did not do well in detecting low-frequency classes (in long-tail datasets)
- BAGS solves this by grouping classes by frequency when training
- BAGS yields significant improvements in mAP in both detection and segmentation models