| author: | joshpapermaster |
| score: | 8 / 10 |
What is the core idea?
Visual recognition models can struggle when there is a long-tailed distribution. Most of the current solutions to the long-tailed problem jointly learn feature representations and train classifiers. This paper decouples their solutions into two processes: representation learning and classification. This is beneficial because they are able to determine which techniques are specifically effective.
Representation learning
- train with different sampling techniques and losses
Classification
- the long tailed classes are recognized by the model from various classifiers
- results from representation learning used to train classifiers
The paper determined the following findings from using their decoupled process:
- instance based sampling provided really good generalized results
- It’s beneficial to adjust the learned decision boundaries of the classifier during training
- done by sampling or weight normalization
- Can apply to any standard network
How is it realized technically?
Experiments covered the following different decoupled techniques to determine which were most effective
Representation Learning:
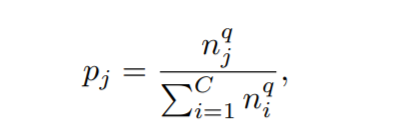
Probability of sampling an image from class j where C is the number of classes
- Instance-balanced sampling
- All examples have same chance of being sampled
- q=1
- Class-balanced sampling
- Each class has same chance of being sampled and then example uniformly sampled within the class
- q=0
- Square-root sampling
- Middle ground between the two previous sampling techniques. Square-roots the total number of images in each class when calculating the ratio of images in specific class / total images
- q=1/2
- Progressively-balanced sampling
- Switches between instance-balanced and class-balanced sampling as learning progresses
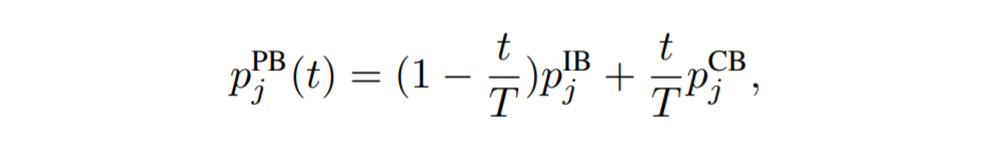 Where T is the total number of epochs
Where T is the total number of epochs
- Switches between instance-balanced and class-balanced sampling as learning progresses
- Loss re-weighting
- Not tested in this paper, but the approaches they did test produced better results
Classification:
- Classifier Re-training (cRT)
- Use fixed representations and randomly re-initialize and optimize the weights for a few epochs using class-balanced sampling
- Nearest Class Mean classifier (NCM)
- First get the mean feature representation for each class, then run nearest neighbors using cosine similarity or Euclidean distance
- τ -normalized classifier (τ -normalized)
- Normalize the weights with a hyperparameter factor τ that is in [0,1] so the weights are rectified smoothly
- Normalize the weights with a hyperparameter factor τ that is in [0,1] so the weights are rectified smoothly
- Learnable weight scaling (LWS)
- Variant of previous method - keeps the representations and weights fixed and learns scaling factors
How well does the paper perform?
Experiments trained on three datasets
- Places-LT (artificially unbalanced from original)
- ImageNet-LT (artificially unbalanced from original)
- iNaturalist 2018 (natural)
The models were then tested on the respective balanced dataset over all classes
The many, medium, few, and all titles below refer to the number of training images the model had for that the class. e.g. the results under “Few” show how well the model performed when the training set only contained less than 20 images
Sampling method critically matters for joint methods, but overall decoupled methods worked better.
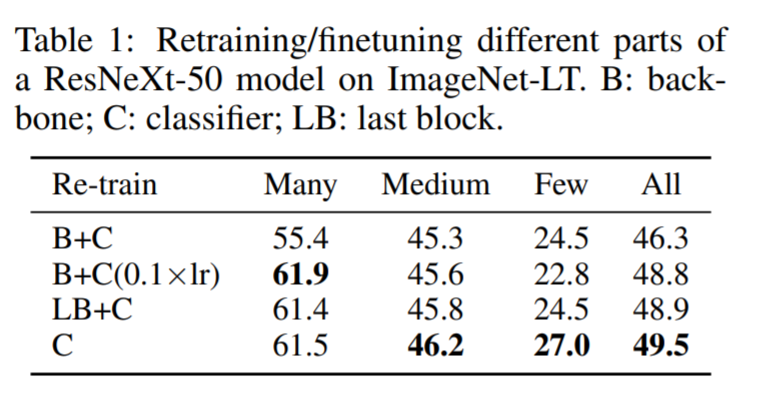
Looking at different areas of restarting learning
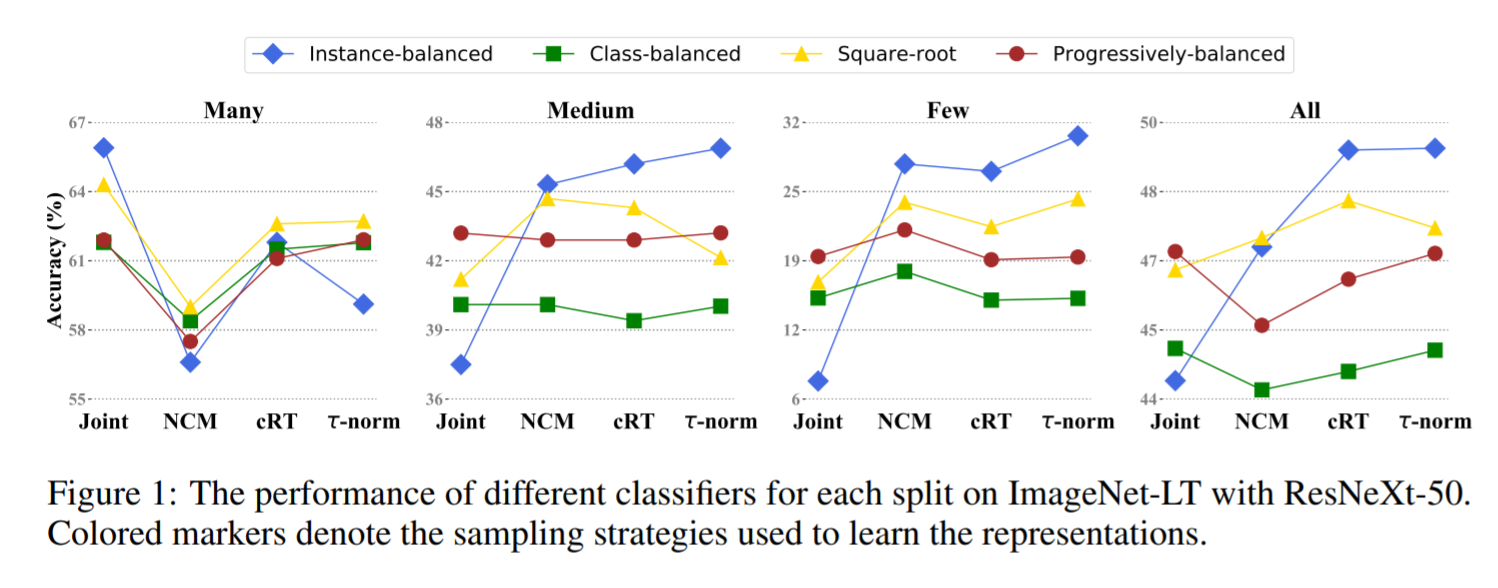
Instance-balanced sampling provides generalizable representations
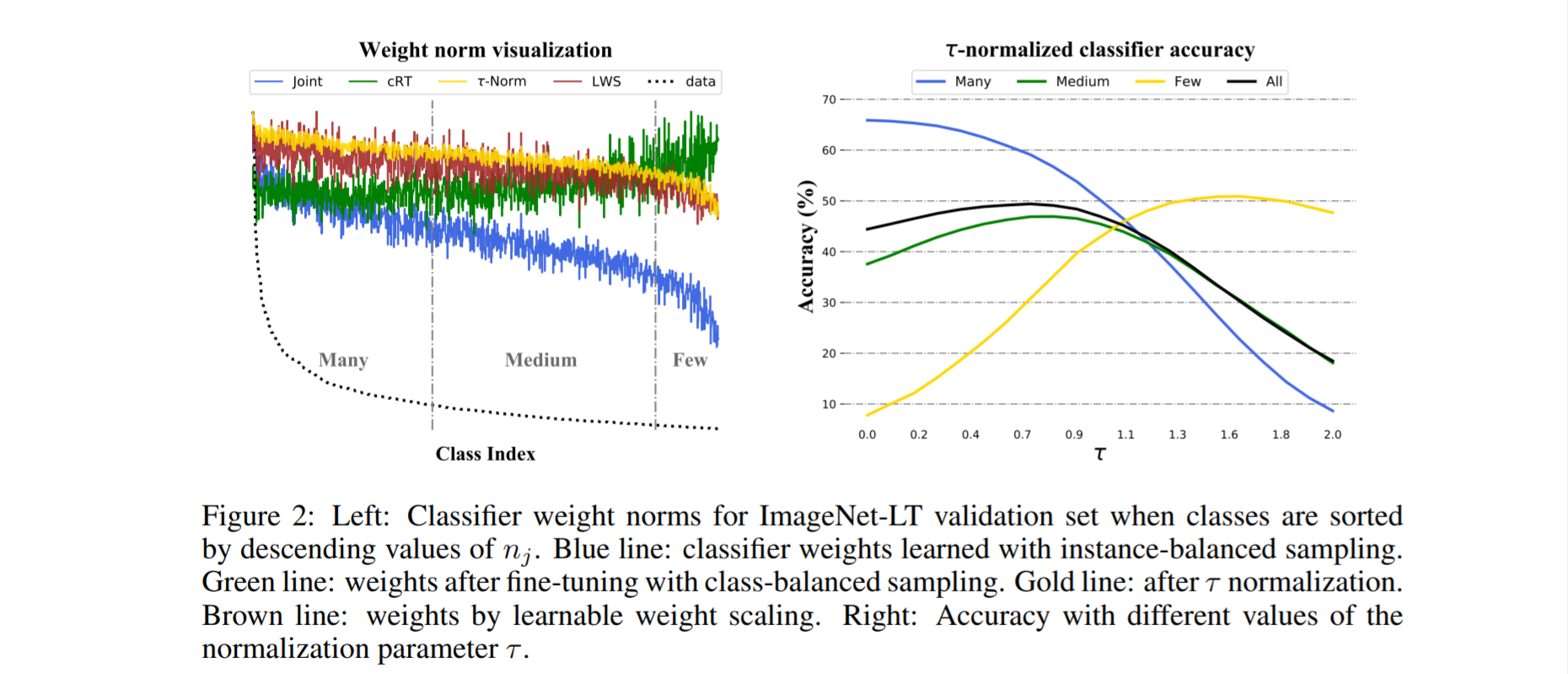
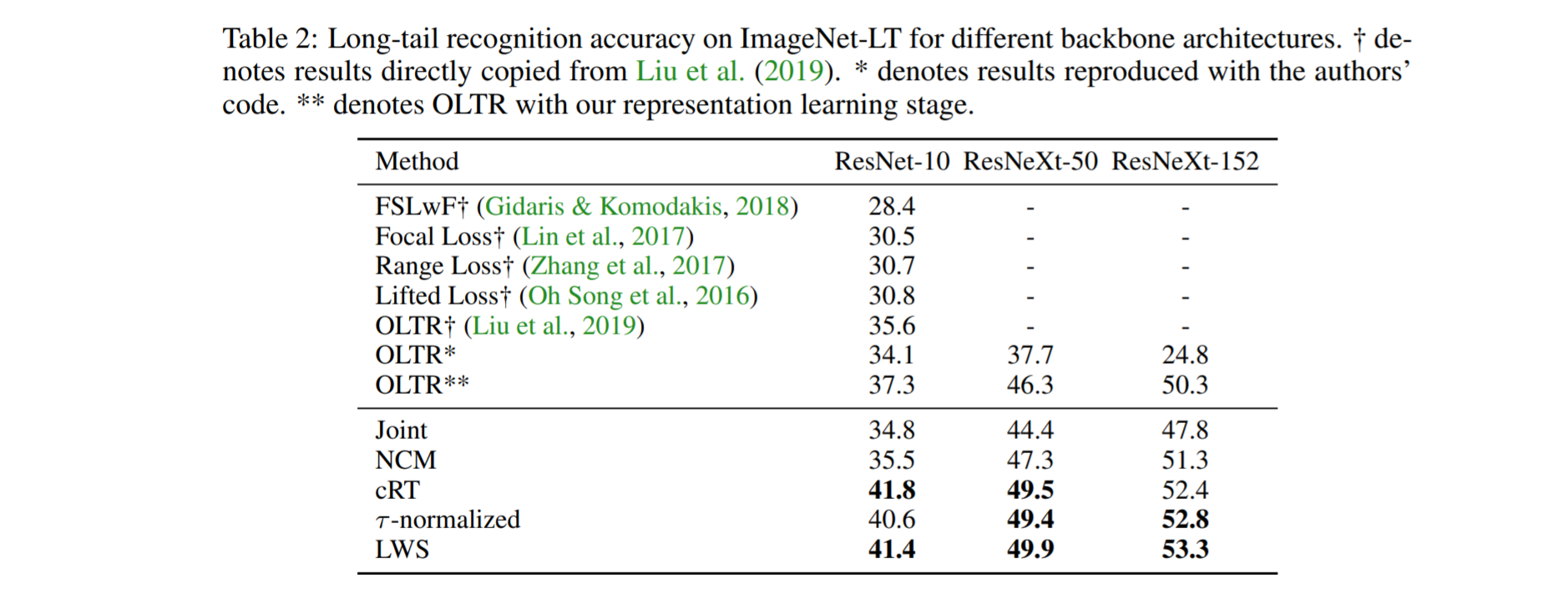
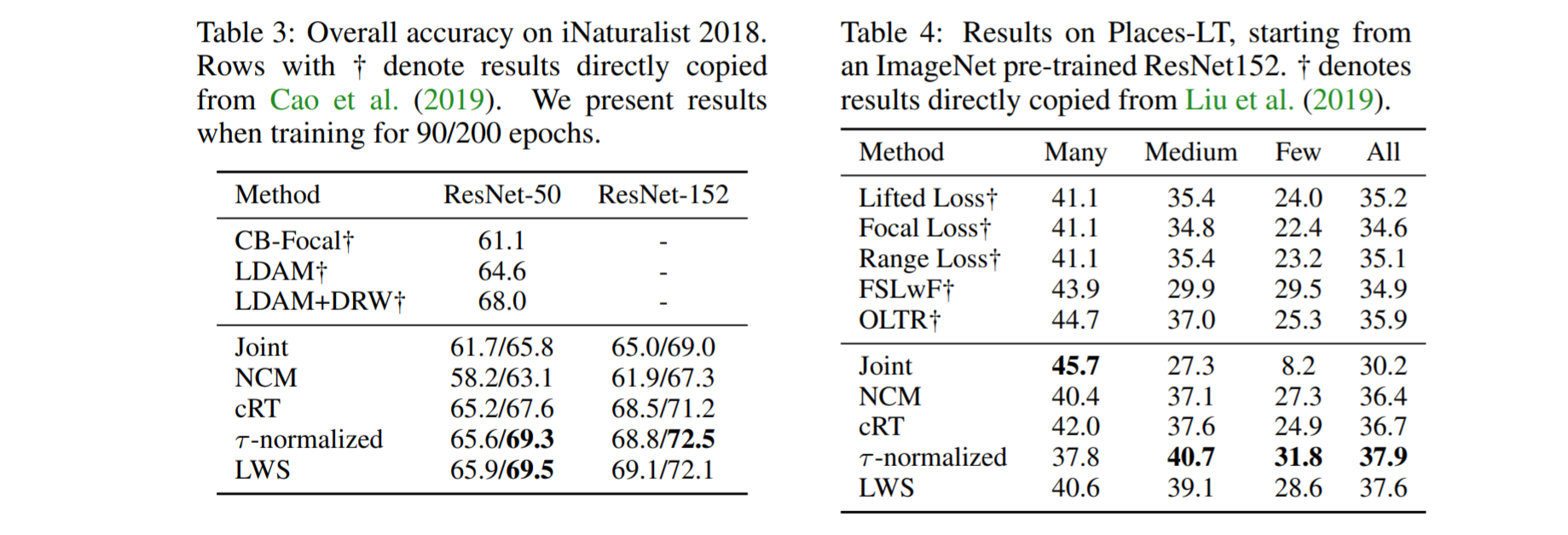
Results continue to show decoupled methods providing the best results
What interesting variants are explored?
- Mentioned but didn’t evaluate loss re-weighting in representation learning
- No other variants besides all the different methods evaluated above
TL;DR
- This paper evaluated different ways of implementing joint and decoupled models for the long-taled distribution problem
- Joint methods were heavily dependent on the type of sampling
- Instance-balanced sampling with re-balancing the classifiers provides state of the art results