| author: | joshpapermaster |
| score: | 9 / 10 |
Core Idea
The intial perceiver model provided good results, but the authors wanted to adapt the model to handle more complex outputs. PerceiverIO can succesfully be used on NLP and visual understanding problems with many different types of outputs, while the intial perceiver model can only handle simpler outputs such as classification.
The idea of perceiver is to create a model that can handle different tasks and perform well with minimal changes needed. They do this by using attention with the intial input to create a latent space that has a constant size. Operations done within the latent space are more scalably efficient with respect to the input because of the smaller size of the latent space dimensions.
How is it realized (technically)?
The structure of perceiverIO is similar to that of perceiver, but with a decoder at the end that can build out the latent space into any dimensions necessary for the given task. They use cross-attention and a query analysis on the output space to map the latent space features to the dynamic structure needed for the output.
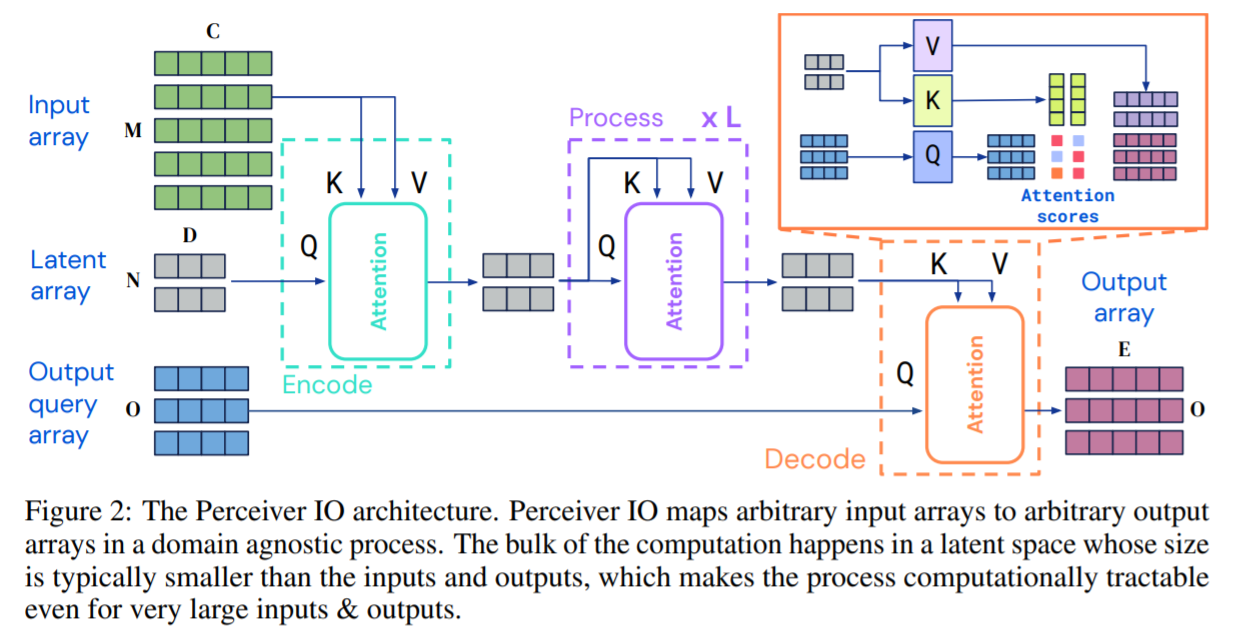
The key to the higher performance of perceiverIO over transformers is the latent space. It allows for higher scalability since all of the computationally expensive aspects are done within the fixed size latent space. The model scales linearly with respect to the input and output.
Related work and why this is more adaptable:
- Multi-task learning
- Ony for computer vision
- Mask-RCNN
- Can handle some complex computer vision tasks, but not language
- Transformers
- Can be used for any task, but are limited by scalability
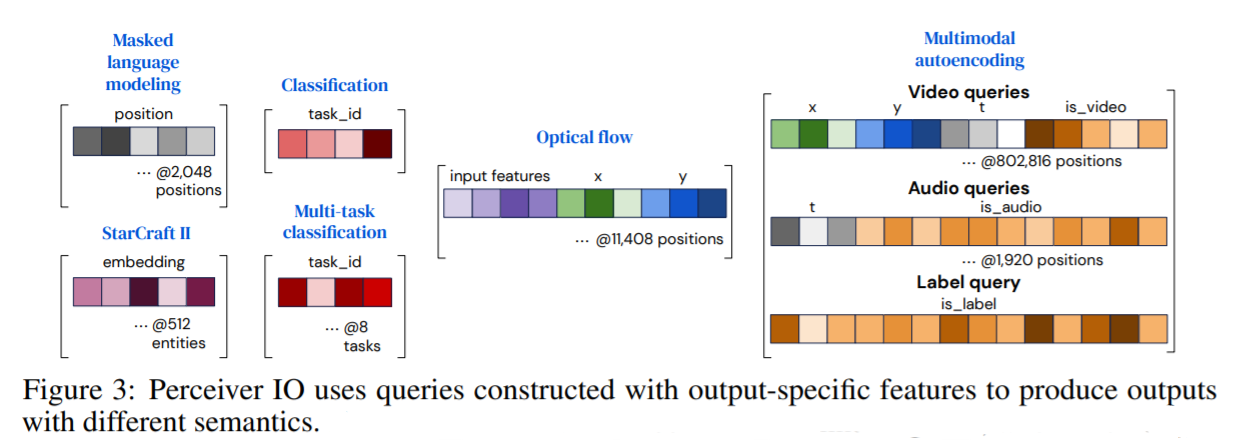
Queries are useful to provide different types of outputs from the same latent space information.
The query for outputs of
- classification is reused for other simple output problems
- spatial or sequence structures use positional encodings
Experiments
Experiments were done on language, visual understanding, videogames, and multi-modal tasks.
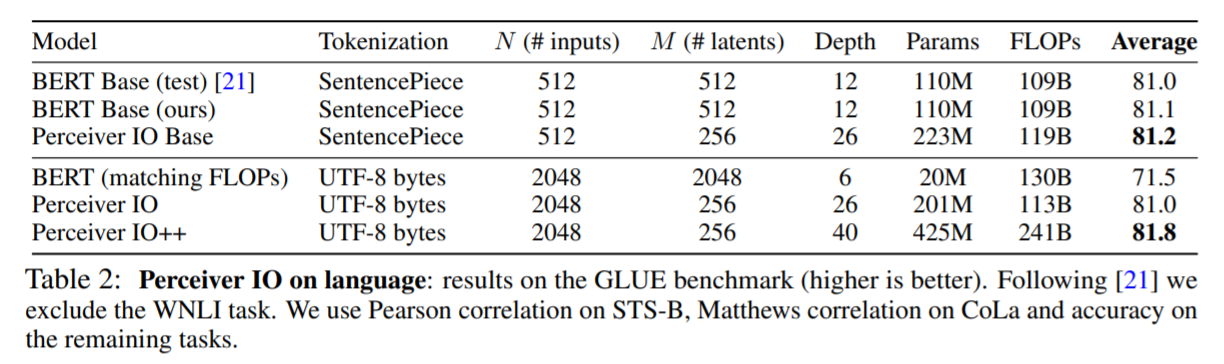
Using the GLUE benchmark, perceiverIO can outperform BERT, while also scaling to larger inputs. As seen in the results below, PerceiverIO on UTF-8 bytes actually performs comparably to BERT using the SentencePiece tokens and is substantially better than BERT on the UTF-8 bytes. For these tests, the tranformers were replaced with perceiverIO architecture.
The muilti-task architecture also performed the best on the GLUE benchmark with respect to single task, shared input token, and task specific input token approaches
PerceiverIO also performed very well on optical flow, multimodal autoencoding, and StarCraft II
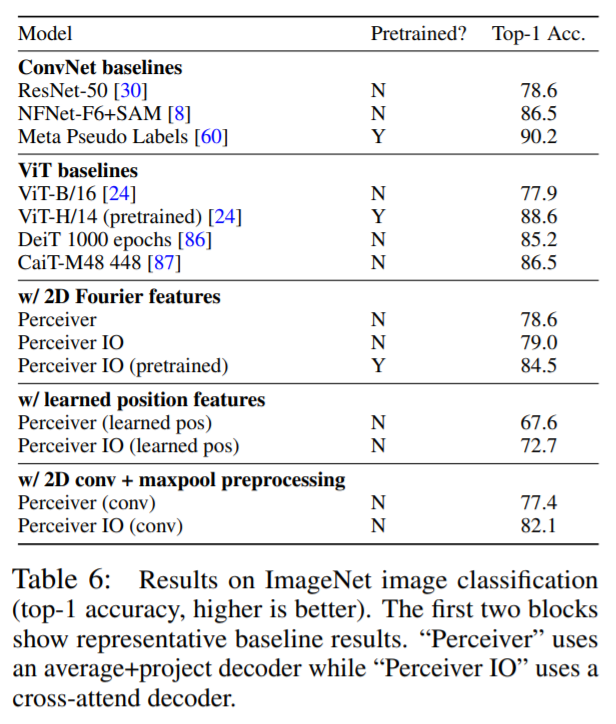
Additionally, the new model performed better than the original architecture on classification of ImageNet
Variants
Other variants discussed were to finetune the size of the latent space specific to the task, allow for generative models, and provide more robustness to adversarial attacks. However, the author did not implement or test these within this paper.
TL;DR
- PerceiverIO improves on the original Perceiver architecture by using a decoder with cross-attention to allow for more complex structures of outputs
- PerceiverIO is more scalable than current popular methods such as transformers due to the fixed size of PerceiverIO’s latent space
- It can perform very well on various tasks with respect to classification, language, visual understanding, videogame strategy, and multi-modal tasks