| author: | philkr |
| score: | 8 / 10 |
The paper introduces DenseNet. The core observation underlying the paper is that residual networks slowly update their features. As a consequence of this many residual block learn similar filters and interpret the same patterns over and over again. DenseNet proposes a very simple solution to this: Reuse outputs of previous layers.
Instead of adding the outputs of a residual connection to the feature map, DenseNet concatenates it along the channel dimension. The figure below shows an example:
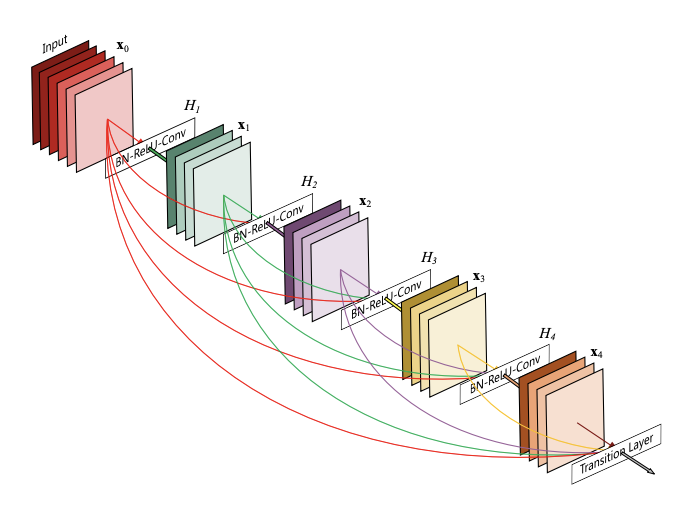
Since each layer receives the features of all preceding layers within a block, the network can use fewer output channels (per-layer). This leads to more compact and networks. Compared to ResNets a DenseNet uses up to \(3\times\) fewer parameters for the same performance.
DenseNet then combines multiple ‘blocks’ of densely connected layers in a network. In between blocks, DenseNet uses a ‘transition’ layer (1x1 conv and average pooling) that reduces the channel dimension.
One issue with DenseNets is that a naive implementation uses a lot of memory during training. It has thus seen little generalization beyond ImageNet.
TL;DR
- Neat evolution of ResNet
- Beautiful mathematical interpretation
- Stellar results