| author: | zhaoyue-zephyrus |
| score: | 10 / 10 |
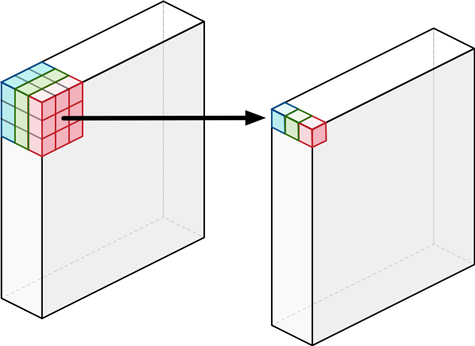
The core idea of MobileNet is to use depthwise separable convolution to achieve better FLOPs-accuracy tradeoff compared to standard convolution.
Each depthwise separable convolution is a 3x3-depthwise convolution + BatchNorm + ReLU plus a 1x1 pointwise convolution + Batch + ReLU.
| layer | Standard Conv | Depthwise Conv | Pointwise (1x1-) Conv |
|---|---|---|---|
| Figure | 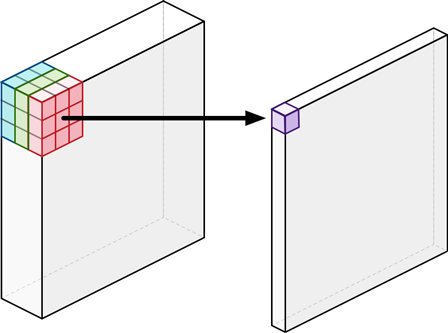 |
 |
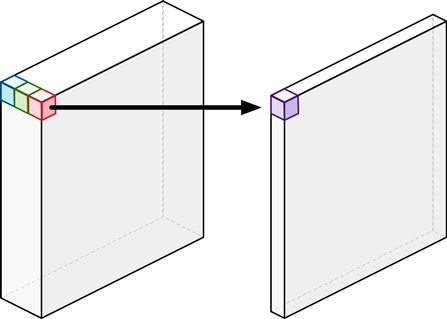 |
| #Param | \(K^2C_{in}C_{out}\) | \(K^2C_{in}\) | \(C_{in}C_{out}\) |
| computation cost | \(K^2C_{in}C_{out}HW\) | \(K^2C_{in}HW\) | \(C_{in}C_{out}HW\) |
| (+ width multiplier) | \(K^2(\alpha C_{in})(\alpha C_{out})HW\) | \(K^2(\alpha C_{in})HW\) | \((\alpha C_{in})(\alpha C_{out})HW\) |
| (+ res. multiplier ) | \(K^2\alpha^2C_{in}C_{out}\rho^2HW\) | \(K^2(\alpha C_{in})\rho^2HW\) | \(\alpha^2C_{in}C_{out}\rho^2HW\) |
(figure source: https://tvm.apache.org/2017/08/22/Optimize-Deep-Learning-GPU-Operators-with-TVM-A-Depthwise-Convolution-Example/)
The reduction is therefore \(\frac{1}{C_{out}} + \frac{1}{K^2}\).
(typical value: \(K=3, C_{in}\in\{32,...,512\}, C_{out}\in\{64,...,1024\}, \alpha\in\{0.25, 0.5, 0.75 \}, \rho\in\{\frac{192}{224},\frac{160}{224},\frac{128}{224} \}\))
In addition, MobileNet introduces two global hyperparameter to shrink model:
-
Width multiplier: linearly scale the number of input & output channels by \(\alpha\).
It also empirically shows that a thinner MobileNet can better maintain accuracy compared to a shallow MobileNet (-> depth matters).
-
Resolution multiplier: Resize the input image by a factor of \(\rho\).
-
By varying \(\alpha\) and \(\rho\), a family of MobileNet newtorks can be instantiated and deployed according to the device’s computation resorce.
-
Accuracy drops off smoothly until \(\alpha = 0.25\) and \(\rho = 0.5\).
The paper conducts extensive studies on various computer vision tasks (ImageNet classification, fine-grained recognition, geo-localization, objection detection, etc.). On ImageNet, e.g., a MobileNet with \(\alpha=0.5\) and input size of 160 (i.e., \(\rho = 0.714\)) is 4% better than AlexNet while being 45x smaller and requiring 9.4x less FLOPs.
TL;DR
- MobileNet proposes depthwise separable convolution for efficient modeling.
- It studies two simple but effective hyper-parameter for modeling shrinking.
- MobileNet family obtains comparable results on various vision tasks with significantly (often 10x) few computations (GFLOPs) and number of parameters.