| author: | joshpapermaster |
| score: | 8 / 10 |
While transformers have become a very popular way of working with sequential data, the equation to determine the attention of the model relies on softmax. This paper provides an alternative trick to approximate the attention in linear time complexity rather than the quadratic time complexity currently required.
The authors suggest a new algorithm for performers called FAVOR+, which stands for fast attention via positive orthogonal random features.
Using this approach brings the time complexity of attention from O(L^2 * d) to O(Lrd)
- This is beneficial because we can control r as a parameter and decrease the computational effort needed.
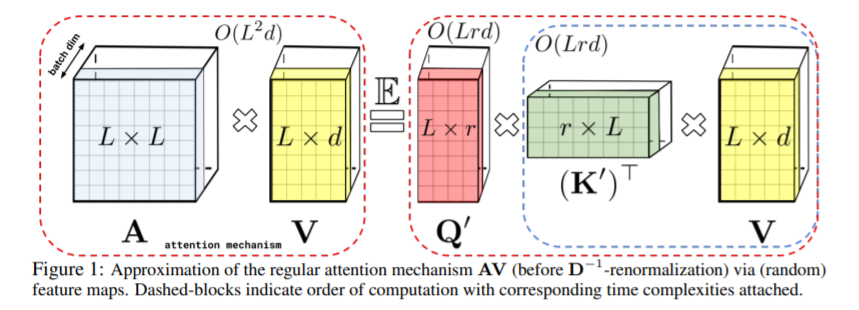
FAVOR+ uses a random feature map to represent the kernel in a lower dimension to keep time complexity low.
There are distinct similarities between the guassian kernel and the softmax kernel. In fact, softmax kernels are equal to renormalized guassian kernels. However, guassian kernels can include negative values which leads to unstable results. Therefore, the random feature map used in this model produces only non-negative scores.
The paper cites a recent publication of the gaussian kernel being effectively represented by a specific random feature map. Since, gaussian kernels can be renormalized to represent softmax kernels, the paper expanded on this random feature map to approximate regular softmax. However, due to the negative input values in guassian kernels, the initial representation was unstable. They countered this by adjusting the feature map to represent a regularized softmax kernel, and subsequently proved the benefits of their method.
The approximation of the regularized softmax kernel was proven to be a universal lower bound of the original softmax kernel. Subsequently, as the approximated values of the new feature map approach 0, the variance of this unbiased positive random feature map also tends to 0. This shows that the random feature map for regularized softmax kernel is an effective and robust approximation for regular softmax attention.
Additionally, the authors included an orothogonality constraint on the random feature map, and proved that this also reduced the error gap when approximating the original softmax kernels.
So they expanded on the feature map of the guassian kernel to represent their new approximation of softmax:
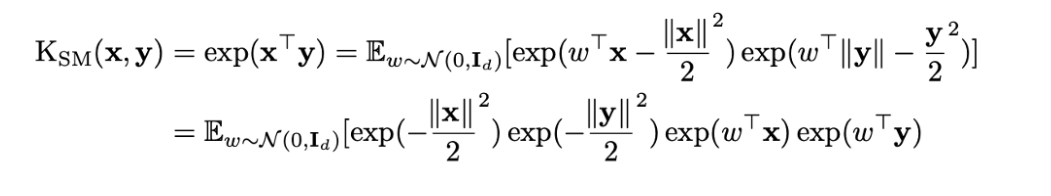
With h(x) in the feature map from the guassian kernel represented as:
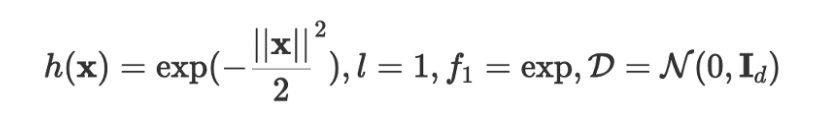
So the original attention of:
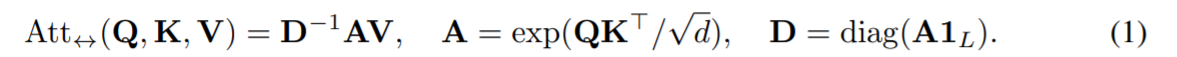
is now approximated by the more efficient version:
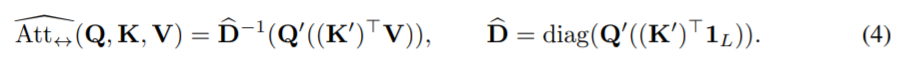
The experiments were done by replacing the attention aspect with FAVOR+ and evaluating the model.
The variants talked about during the experiments include Reformer (unidirectional) and Linformer (bidirectional) on the PG19 dataset.
The computational speed results of these tests backup the theoretical analysis. Performers are able to reach linear time complexity and subquadratic memory usage.
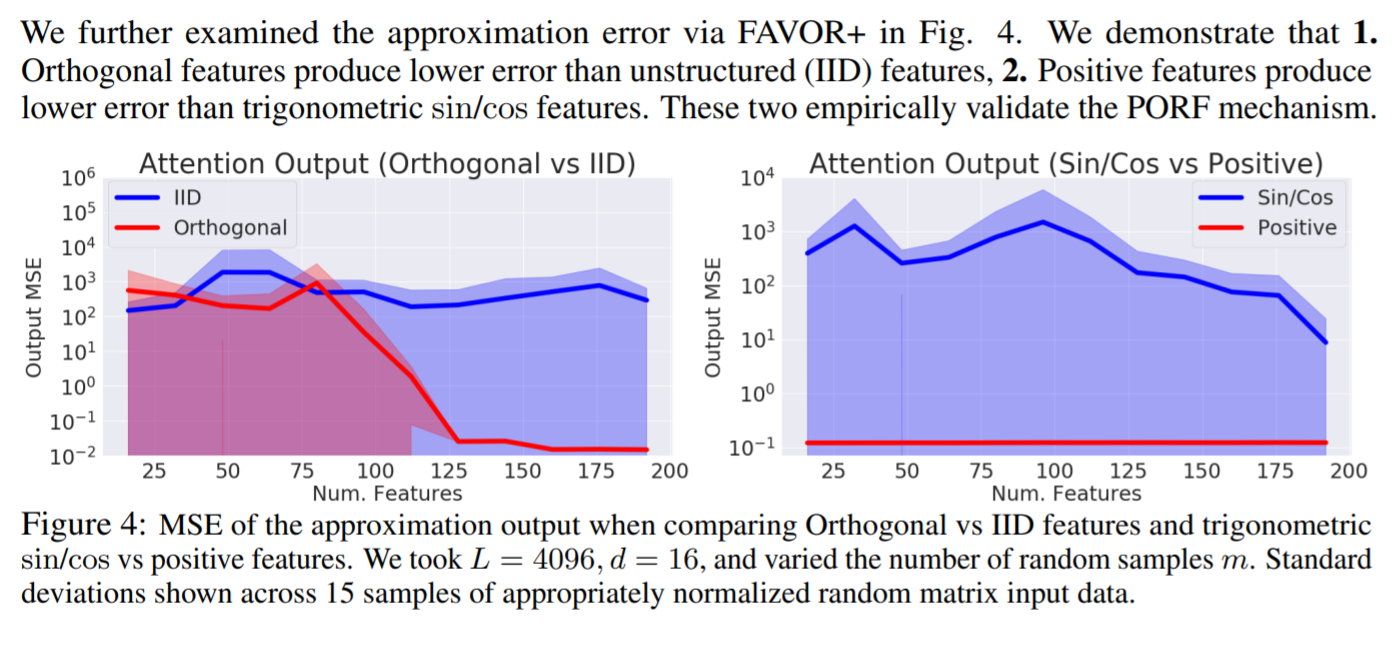
It was also proven that FAVOR+ produces better results than the IID and trigonometric features:
Experiments proved that performers worked with already trained models with minor finetuning.
Additionally, the Performer RELU had significantly higher accuracy than both Reformer and Linformer on the bidirectional and undirectional cases of the protein sequences from the TrEMBL. The Performer softmax also had good results, and received the same results as the original softmax.
TL;DR
- Performers provide a time and space efficient approximation of attention with low estimation variance, strong theoretical guarantees, and uniform convergence using the FAVOR+ approach
- They overcome the shortcomings of previous approximations that rely on priors or using localized data
- Performers work with transformers and can be extended to various benefits in fields such as biology, environment, research on transformers, and more.