| author: | mattkelleher |
| score: | 9 / 10 |
Core Idea
The paper aims to create a class of Normalizer Free (NF) ResNets that are competative with the current state-of-the-art. An Adaptive Gradient Clipping (AGC) method is introduced to achieve these goals with NF ResNets.
Motivation
While batch normalization has been shown to be effective in practice, it is difficult to explain why it works and has some practical drawbacks.
The authors outline three of these drawbakcs which are summarized below:
- Batch Normalization is computationally expensive: requires signifcant memory overhead and can be slow due to gradient evaluations.
- Models behave differently during training and testing.
- Batch normalization violates the assumption that training examples are indepenent of each other within the same minibatch.
The goal of this paper is to address these issues and create normalizer free ResNets with comperable accuracies as the current state-of-the-art, many of which use normalization.
Technical Details
Traditional gradient clipping methods are defined:
\(G = \pdv{L}{\Theta }\) where \(L\) is loss and \(\Theta\) is all of the model parameters.
\(\lambda\) is the clipping parameter
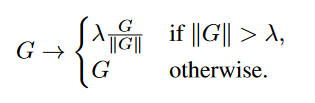
While this traditional clipping does allow for larger batch sizes it is very sensative to \(\lambda\).
Adaptive Gradient Clipping (AGC):
\(W_{i}^{l}\) is the \(i^{th}\) row of the weight matrix of the \(l^{th}\) layer of the network
\(G^l\) is the gradient w.r.t \(W^l\) and \(G_{i}^l\) is the \(i^{th}\) row of \(G^l\)
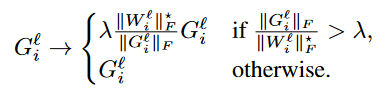
The idea here is that if the norm of the weight updates in a single layer (\(\Delta\) weights) is much larger than the norm of the current weights in that layer then training will likely become unstable.
Normalizer Free ResNets and Results
Networks are designed to optimize training latency and accuracy. The authors manually explore the architecture space and used SE-ResNeXt-D with GELU activations as a baseline model which they further modified. Networks are trained with Nesterov Momentum, Adaptive Gradient Clipping with large batch sizes, and aggresive data augmentation.
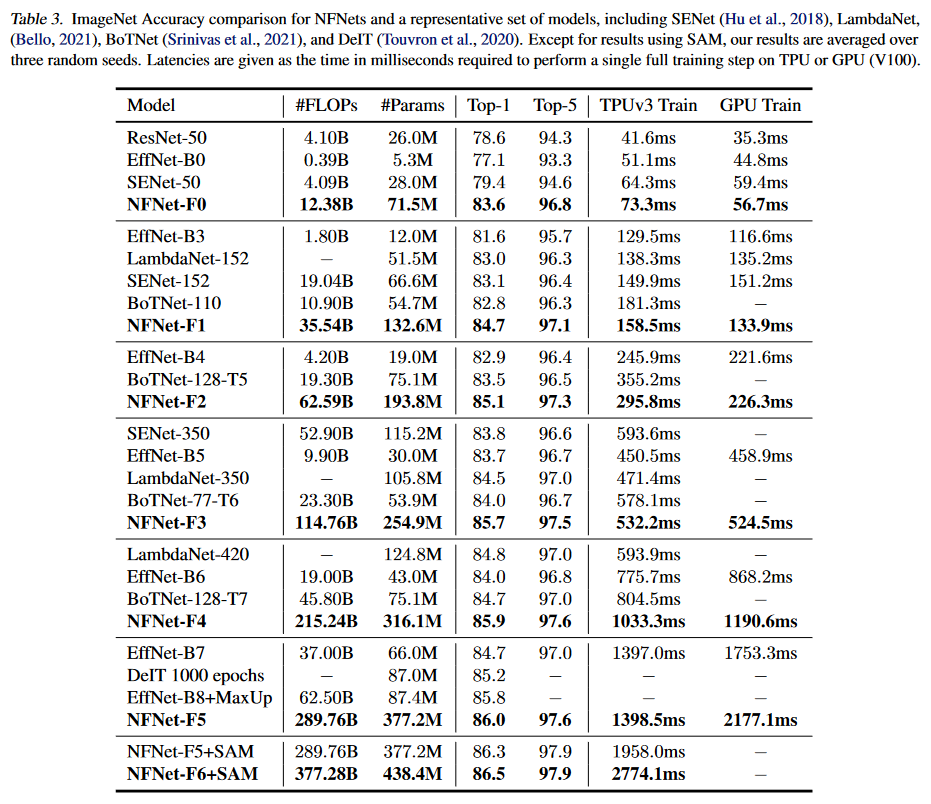
Note that the NF-ResNets not only set state-of-the-art accuracies, they also have competative training latencies and are faster than some of the other top models despite having significantly more parameters and theoretical FLOPs.
Normalizer Free Networks with Transfer Learning
NF Networks are pretrained on 300 million labeled images and then fine tuned to ImageNet. These networks outperform the analogous networks that use Batch Normalization which the authors claim shows that batch normalization may actually hurt transfer learning techniques.
![]()
TL;DR
- Introduces an adaptive gradient clipping technique that is effective without any batch normalization present in network
- Decreass training time without losing accuracy in smaller models, set new top-1 state-of-the-art accuracy for ImageNet with a large NF-ResNet model
- Out performs BN-ResNet models on transfer learning tasks