Does Computer Vision Matter for Action?
Brady Zhou, Philipp Krähenbühl, Vladlen KoltunScience Robotics 2019
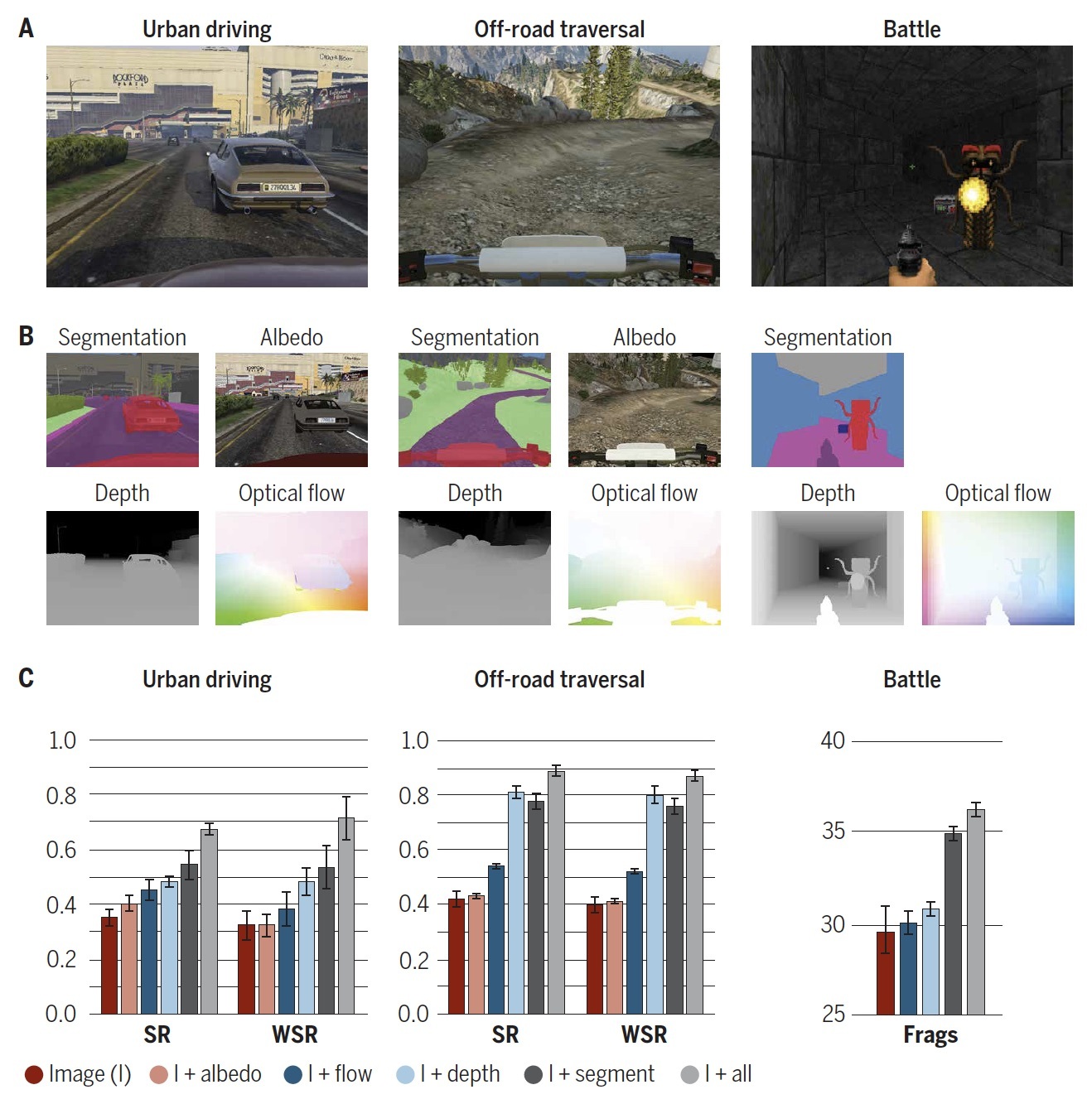
Computer vision produces representations of scene content. Much computer vision research is predicated on the assumption that these intermediate representations are useful for action. Recent work at the intersection of machine learning and robotics calls this assumption into question by training sensorimotor systems directly for the task at hand, from pixels to actions, with no explicit intermediate representations. Thus the central question of our work: Does computer vision matter for action? We probe this question and its offshoots via immersive simulation, which allows us to conduct controlled reproducible experiments at scale. We instrument immersive three-dimensional environments to simulate challenges such as urban driving, off-road trail traversal, and battle. Our main finding is that computer vision does matter. Models equipped with intermediate representations train faster, achieve higher task performance, and generalize better to previously unseen environments.