Multimodal Virtual Point 3D Detection
Tianwei Yin, Xingyi Zhou, Philipp KrähenbühlNeurIPS 2021
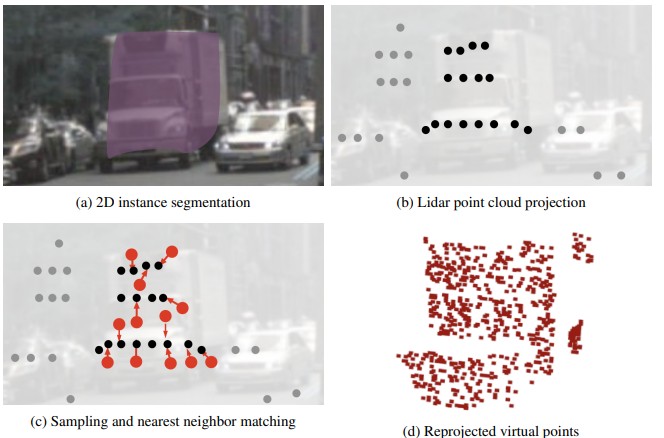
Lidar-based sensing drives current autonomous vehicles. Despite rapid progress, current Lidar sensors still lag two decades behind traditional color cameras in terms of resolution and cost. For autonomous driving, this means that large objects close to the sensors are easily visible, but far-away or small objects comprise only one measurement or two. This is an issue, especially when these objects turn out to be driving hazards. On the other hand, these same objects are clearly visible in onboard RGB sensors. In this work, we present an approach to seamlessly fuse RGB sensors into Lidar-based 3D recognition. Our approach takes a set of 2D detections to generate dense 3D virtual points to augment an otherwise sparse 3D point cloud. These virtual points naturally integrate into any standard Lidar-based 3D detectors along with regular Lidar measurements. The resulting multi-modal detector is simple and effective. Experimental results on the large-scale nuScenes dataset show that our framework improves a strong CenterPoint baseline by a significant 6.6 mAP, and outperforms competing fusion approaches. Code and more visualizations are available at https://tianweiy.github.io/mvp/.