Monocular plan view networks for autonomous driving
Dequan Wang, Coline Devin, Qi-Zhi Cai, Philipp Krähenbühl, Trevor DarrellIROS 2019
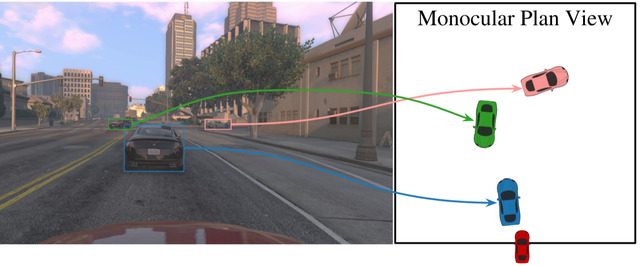
Convolutions on monocular dash cam videos capture spatial invariances in the image plane but do not explicitly reason about distances and depth. We propose a simple transformation of observations into a bird’s eye view, also known as plan view, for end-to-end control. We detect vehicles and pedestrians in the first person view and project them into an overhead plan view. This representation provides an abstraction of the environment from which a deep network can easily deduce the positions and directions of entities. Additionally, the plan view enables us to leverage advances in 3D object detection in conjunction with deep policy learning. We evaluate our monocular plan view network on the photo-realistic Grand Theft Auto V simulator. A network using both a plan view and front view causes less than half as many collisions as previous detection-based methods and an order of magnitude fewer collisions than pure pixel-based policies.