Memory Optimization for Deep Networks
Aashaka Shah, Chao-Yuan Wu, Jayashree Mohan, Vijay Chidambaram, Philipp KrähenbühlICLR 2021
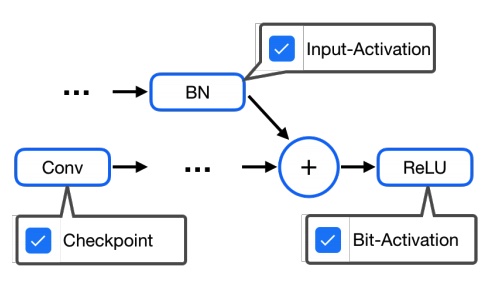
Deep learning is slowly, but steadily, hitting a memory bottleneck. While the tensor computation in top-of-the-line GPUs increased by 32x over the last five years, the total available memory only grew by 2.5x. This prevents researchers from exploring larger architectures, as training large networks requires more memory for storing intermediate outputs. In this paper, we present MONeT, an automatic framework that minimizes both the memory footprint and computational overhead of deep networks. MONeT jointly optimizes the checkpointing schedule and the implementation of various operators. MONeT is able to outperform all prior hand-tuned operations as well as automated checkpointing. MONeT reduces the overall memory requirement by 3x for various PyTorch models, with a 9-16% overhead in computation. For the same computation cost, MONeT requires 1.2-1.8x less memory than current state-of-the-art automated checkpointing frameworks.